De Deep Residual Shrinkage Network is een verbeterde variant van de Deep Residual Network (ResNet). In essentie is het een integratie van de Deep Residual Network, attention mechanisms en soft thresholding functies.
De werking van de Deep Residual Shrinkage Network kan tot op zekere hoogte als volgt worden begrepen: via een attention mechanism worden onbelangrijke features opgemerkt, die vervolgens door een soft thresholding functie op nul worden gezet. Anders gezegd: het mechanisme merkt belangrijke features op en behoudt deze. Dit versterkt het vermogen van het deep neural network om nuttige features te extracten uit signalen die ruis bevatten.
1. Motivatie voor het onderzoek
Ten eerste: bij het classificeren van samples is de aanwezigheid van ruis – zoals Gaussische ruis, roze ruis en Laplace-ruis – onvermijdelijk. In bredere zin bevatten samples vaak informatie die niet relevant is voor de huidige classificatietaak; ook dit kan worden gezien als ruis. Deze ruis kan de prestaties van de classificatie negatief beïnvloeden. (Soft thresholding is een cruciale stap in veel algoritmen voor signaalruisonderdrukking).
Een voorbeeld: tijdens een gesprek langs de weg kan het stemgeluid vermengd raken met toeterende auto’s of bandengeruis. Bij speech recognition op deze signalen zal het resultaat onvermijdelijk worden beïnvloed door deze achtergrondgeluiden. Vanuit een deep learning-perspectief zouden de features die corresponderen met dat getoeter en bandengeruis binnen het deep neural network verwijderd moeten worden, om te voorkomen dat ze de spraakherkenning verstoren.
Ten tweede: zelfs binnen dezelfde dataset varieert de hoeveelheid ruis vaak per sample. (Dit vertoont overeenkomsten met attention mechanisms; neem een dataset met afbeeldingen als voorbeeld: de locatie van het doelobject kan per foto verschillen, en het attention mechanism kan focussen op de specifieke locatie van het object in elke afzonderlijke afbeelding).
Stel dat we bijvoorbeeld een honden-en-katten-classifier trainen. Neem vijf afbeeldingen met het label “hond”. De eerste afbeelding bevat misschien een hond én een muis, de tweede een hond én een gans, de derde een hond én een kip, de vierde een hond én een ezel, en de vijfde een hond én een eend. Tijdens het trainen van de classifier ondervinden we onvermijdelijk storing van deze irrelevante objecten (muis, gans, kip, ezel en eend), wat leidt tot een lagere classificatie-nauwkeurigheid (accuracy). Als we in staat zijn om deze irrelevante objecten op te merken en de bijbehorende features te verwijderen, kunnen we de nauwkeurigheid van de classifier verbeteren.
2. Soft Thresholding
Soft thresholding is een kernstap in veel algoritmen voor signaalruisonderdrukking. Het verwijdert features waarvan de absolute waarde lager is dan een bepaalde drempelwaarde (threshold) en “krimpt” features die daarboven zitten richting nul. Dit kan worden geïmplementeerd met de volgende formule:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]De afgeleide van de output van soft thresholding ten opzichte van de input is:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Zoals hierboven te zien is, is de afgeleide van soft thresholding ofwel 1 ofwel 0. Deze eigenschap is identiek aan die van de ReLU activatiefunctie. Hierdoor kan soft thresholding ook het risico verkleinen dat deep learning-algoritmen last krijgen van gradient vanishing en gradient exploding.
Bij het instellen van de threshold in de soft thresholding functie moet aan twee voorwaarden worden voldaan: ten eerste moet de threshold een positief getal zijn; ten tweede mag de threshold niet groter zijn dan de maximale waarde van het inputsignaal, anders wordt de output volledig nul.
Tegelijkertijd is het wenselijk dat de threshold aan een derde voorwaarde voldoet: elk sample zou, gebaseerd op zijn eigen ruisniveau, een eigen onafhankelijke threshold moeten hebben.
Dit komt doordat de hoeveelheid ruis vaak varieert tussen samples. Het komt bijvoorbeeld vaak voor dat binnen dezelfde dataset Sample A weinig ruis bevat en Sample B veel ruis. Als we dan soft thresholding toepassen in een ruisonderdrukkingsalgoritme, zou Sample A een kleinere threshold moeten gebruiken en Sample B een grotere. Hoewel deze features en thresholds in een deep neural network hun expliciete fysische betekenis verliezen, blijft de onderliggende logica hetzelfde. Oftewel: elk sample heeft een eigen, onafhankelijke threshold nodig.
3. Attention Mechanism
Het concept van een attention mechanism is vrij eenvoudig te begrijpen binnen het vakgebied Computer Vision. Het visuele systeem van dieren kan snel een volledige omgeving scannen, een doelobject ontdekken en vervolgens de aandacht (attention) focussen op dat object om meer details te zien, terwijl irrelevante informatie wordt onderdrukt. Zie voor details de literatuur over attention mechanisms.
Squeeze-and-Excitation Network (SENet) is een relatief nieuwe deep learning-methode die gebruikmaakt van attention mechanisms. De bijdrage van verschillende feature channels aan een classificatietaak verschilt vaak per sample. SENet gebruikt een klein sub-netwerk om een set gewichten (weights) te verkrijgen. Deze gewichten worden vervolgens vermenigvuldigd met de features van de respectievelijke channels om de grootte van de features per channel aan te passen. Dit proces kan worden gezien als het toepassen van verschillende maten van “aandacht” op de verschillende feature channels.
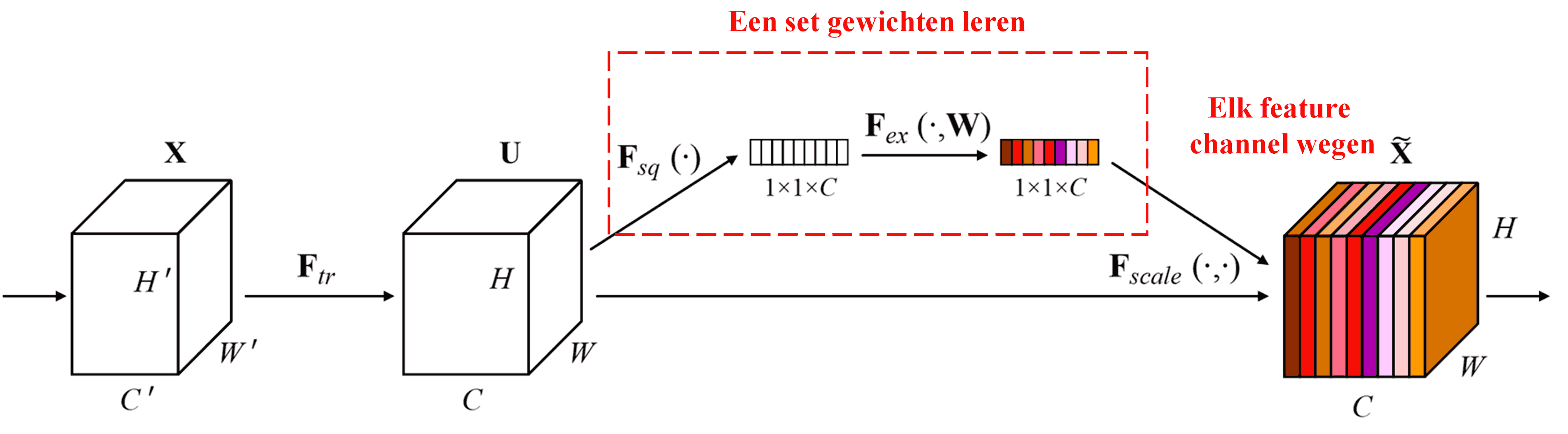
Op deze manier heeft elk sample zijn eigen onafhankelijke set gewichten. Met andere woorden: de gewichten zijn voor elk willekeurig paar samples verschillend. In SENet is het specifieke pad om deze gewichten te verkrijgen: “Global Pooling → Fully Connected Layer → ReLU functie → Fully Connected Layer → Sigmoid functie”.
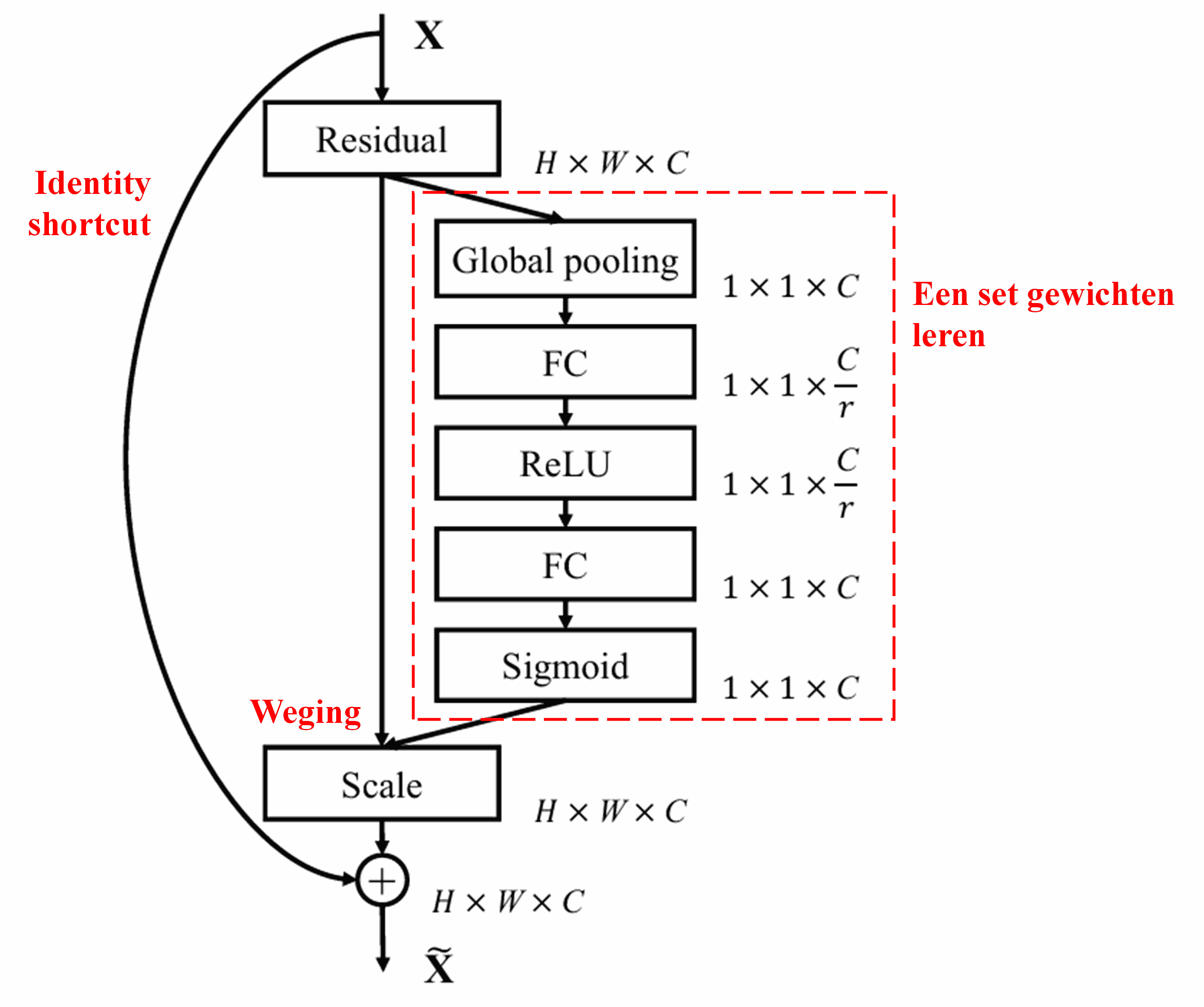
4. Soft Thresholding met Deep Attention Mechanism
De Deep Residual Shrinkage Network maakt gebruik van de hierboven genoemde sub-netwerkstructuur van SENet om soft thresholding te realiseren binnen een deep attention mechanism. Via het sub-netwerk (aangegeven in de rode kaders) kan een set thresholds worden geleerd om soft thresholding toe te passen op elk feature channel.
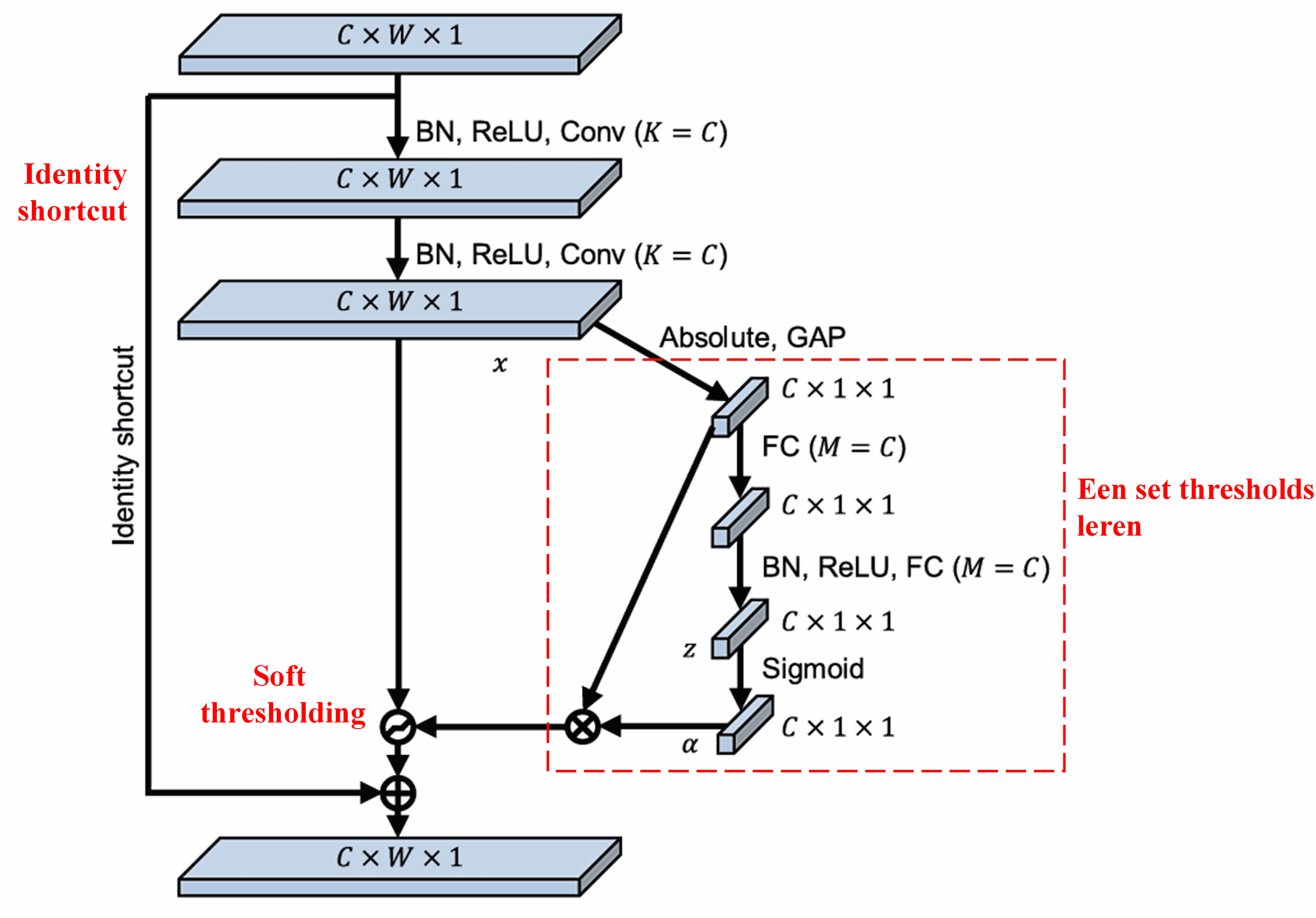
In dit sub-netwerk wordt eerst de absolute waarde genomen van alle features in de input feature map. Vervolgens wordt via global average pooling en middeling een feature verkregen, die we noteren als A. In het andere pad wordt de feature map na global average pooling ingevoerd in een klein fully connected network. Dit netwerk gebruikt een Sigmoid-functie als laatste laag om de output te normaliseren tussen 0 en 1, wat een coëfficiënt oplevert, genoteerd als α. De uiteindelijke threshold kan worden uitgedrukt als α×A. De threshold is dus: een getal tussen 0 en 1 vermenigvuldigd met het gemiddelde van de absolute waarden van de feature map. Deze methode garandeert niet alleen dat de threshold positief is, maar ook dat deze niet te groot wordt.
Bovendien krijgen verschillende samples hierdoor verschillende thresholds. Daarom kan dit tot op zekere hoogte worden begrepen als een speciaal attention mechanism: het merkt features op die niet relevant zijn voor de huidige taak, transformeert deze via twee convolutional layers naar waarden dicht bij 0, en zet ze via soft thresholding op nul; of anders gezegd: het merkt features op die wél relevant zijn voor de taak, transformeert deze via twee convolutional layers naar waarden ver van 0, en behoudt deze features.
Tot slot wordt de volledige Deep Residual Shrinkage Network geconstrueerd door een bepaald aantal basismodules te stapelen, samen met convolutional layers, Batch Normalization, activatiefuncties, global average pooling en een fully connected outputlaag.
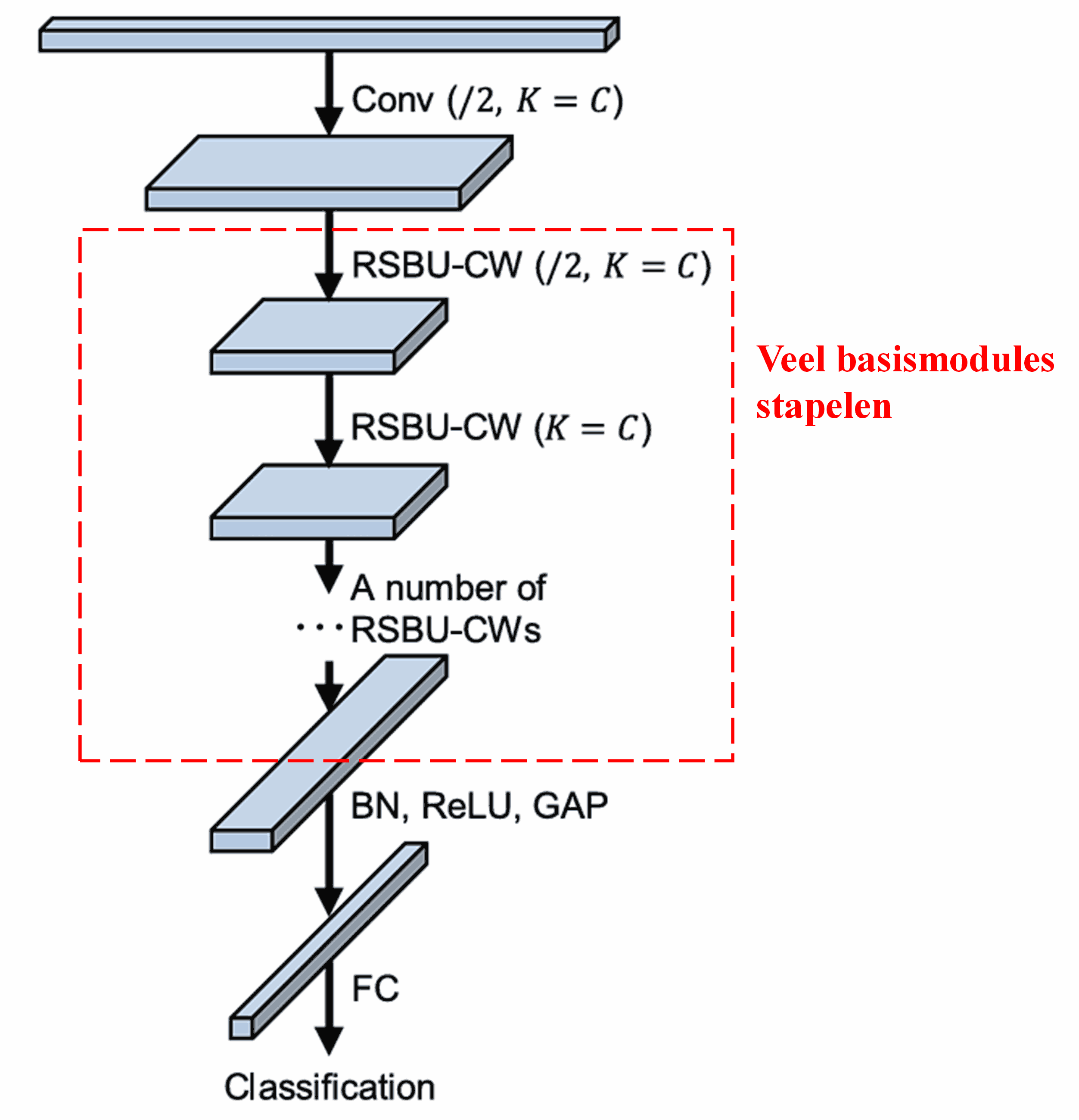
5. Generaliseerbaarheid
De Deep Residual Shrinkage Network is in feite een generieke methode voor feature learning. Dit komt doordat samples in veel feature learning-taken min of meer ruis en irrelevante informatie bevatten. Deze ruis en irrelevante informatie kunnen een negatieve invloed hebben op het leerproces. Bijvoorbeeld:
Bij image classification: als een afbeelding tegelijkertijd veel andere objecten bevat, kunnen deze objecten worden opgevat als “ruis”. De Deep Residual Shrinkage Network kan mogelijk via het attention mechanism deze “ruis” opmerken en vervolgens via soft thresholding de features die bij deze “ruis” horen op nul zetten. Dit kan de nauwkeurigheid van de beeldclassificatie verhogen.
Bij speech recognition: in omgevingen met veel achtergrondgeluid, zoals tijdens een gesprek langs de weg of in een fabriekshal, kan de Deep Residual Shrinkage Network de nauwkeurigheid van de spraakherkenning verbeteren, of op zijn minst een strategie bieden die kan leiden tot betere prestaties.
Referenties
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Impact
Volgens Google Scholar is deze paper al meer dan 1400 keer geciteerd.
Volgens een conservatieve schatting is de Deep Residual Shrinkage Network in meer dan 1000 publicaties direct toegepast of in verbeterde vorm gebruikt in uiteenlopende gebieden, waaronder werktuigbouwkunde, energiesystemen, computer vision, medische technologie, spraakverwerking, tekstanalyse, radar en remote sensing.