La Deep Residual Shrinkage Network (DRSN) è una variante migliorata della Deep Residual Network (ResNet). In sostanza, rappresenta un’integrazione tra le ResNet, i meccanismi di attenzione e le funzioni di Soft Thresholding.
In una certa misura, il principio di funzionamento della Deep Residual Shrinkage Network può essere interpretato così: attraverso il meccanismo di attenzione, la rete individua le feature non importanti e le azzera tramite la funzione di Soft Thresholding; analogamente, individua le feature importanti e le preserva. Questo processo potenzia la capacità della rete neurale profonda di estrarre feature utili da segnali affetti da rumore.
1. Motivazione della Ricerca
In primo luogo, nei compiti di classificazione, è inevitabile che i campioni contengano del rumore, come il rumore Gaussiano, il rumore rosa, il rumore Laplaciano, ecc. In senso più ampio, i campioni contengono spesso informazioni non pertinenti al task di classificazione corrente; anche queste possono essere considerate “rumore” e possono impattare negativamente sulle performance di classificazione. (Il Soft Thresholding è un passaggio chiave in molti algoritmi di signal denoising).
Ad esempio, durante una conversazione a bordo strada, la voce potrebbe mescolarsi con il suono dei clacson o con il rumore di rotolamento degli pneumatici. Eseguendo il riconoscimento vocale su questi segnali, l’efficacia sarà inevitabilmente compromessa da questi suoni di sottofondo. Nella prospettiva del Deep Learning, le feature corrispondenti a clacson e rumori stradali dovrebbero essere eliminate all’interno della rete neurale, per evitare che influenzino il risultato del riconoscimento.
In secondo luogo, anche all’interno dello stesso dataset, la quantità di rumore varia spesso da campione a campione. (Questo concetto è affine al meccanismo di attenzione: prendendo come esempio un dataset di immagini, la posizione dell’oggetto target può variare; il meccanismo di attenzione è in grado di focalizzarsi sulla posizione specifica del target in ogni immagine).
Per esempio, addestrando un classificatore cane/gatto con 5 immagini etichettate come “cane”: la prima potrebbe contenere un cane e un topo, la seconda un cane e un’oca, la terza un cane e una gallina, la quarta un cane e un asino, la quinta un cane e un’anatra. Durante il training, il modello subirebbe l’interferenza di oggetti irrilevanti (topi, oche, ecc.), causando un calo dell’accuratezza. Se fossimo in grado di individuare questi elementi irrilevanti ed eliminare le feature corrispondenti, potremmo migliorare l’accuratezza del classificatore.
2. Soft Thresholding
Il Soft Thresholding è il passaggio centrale di molti algoritmi di riduzione del rumore. Esso elimina le feature il cui valore assoluto è inferiore a una certa soglia e “contrae” verso lo zero quelle il cui valore assoluto è superiore. Questa operazione può essere realizzata attraverso la seguente formula:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]La derivata dell’uscita del Soft Thresholding rispetto all’ingresso è:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Come si nota, la derivata è 1 oppure 0. Questa proprietà è identica a quella della funzione di attivazione ReLU. Di conseguenza, il Soft Thresholding riduce anche il rischio di gradient vanishing (scomparsa del gradiente) e gradient exploding (esplosione del gradiente) negli algoritmi di deep learning.
Nella funzione di Soft Thresholding, l’impostazione della soglia deve soddisfare due condizioni: primo, la soglia deve essere positiva; secondo, non può superare il valore massimo del segnale in ingresso, altrimenti l’uscita sarebbe interamente zero.
Inoltre, è preferibile che la soglia soddisfi una terza condizione: ogni campione dovrebbe avere una propria soglia indipendente, basata sul proprio contenuto di rumore.
Questo perché il livello di rumore varia tra i campioni. Spesso, nello stesso dataset, il campione A contiene poco rumore, mentre il campione B ne contiene molto. Pertanto, applicando il Soft Thresholding, il campione A dovrebbe adottare una soglia più bassa, e il campione B una più alta. Nelle reti neurali profonde, sebbene feature e soglie perdano un significato fisico esplicito, la logica di base rimane valida: ogni campione necessita di una soglia adattiva al proprio livello di rumore.
3. Meccanismo di Attenzione
Il meccanismo di attenzione è un concetto intuitivo nella Computer Vision. Il sistema visivo animale scansiona rapidamente un’area, individua il target e concentra l’attenzione su di esso per estrarre dettagli, sopprimendo le informazioni irrilevanti. Per approfondimenti, si rimanda alla letteratura specifica.
La Squeeze-and-Excitation Network (SENet) è un metodo di deep learning recente basato sull’attenzione. Il contributo dei vari canali delle feature (feature channels) alla classificazione varia tra i campioni. La SENet usa una piccola sottorete per ottenere un set di pesi, che vengono moltiplicati per le feature dei rispettivi canali per regolarne l’ampiezza. Questo processo equivale ad applicare diversi livelli di “attenzione” ai canali.
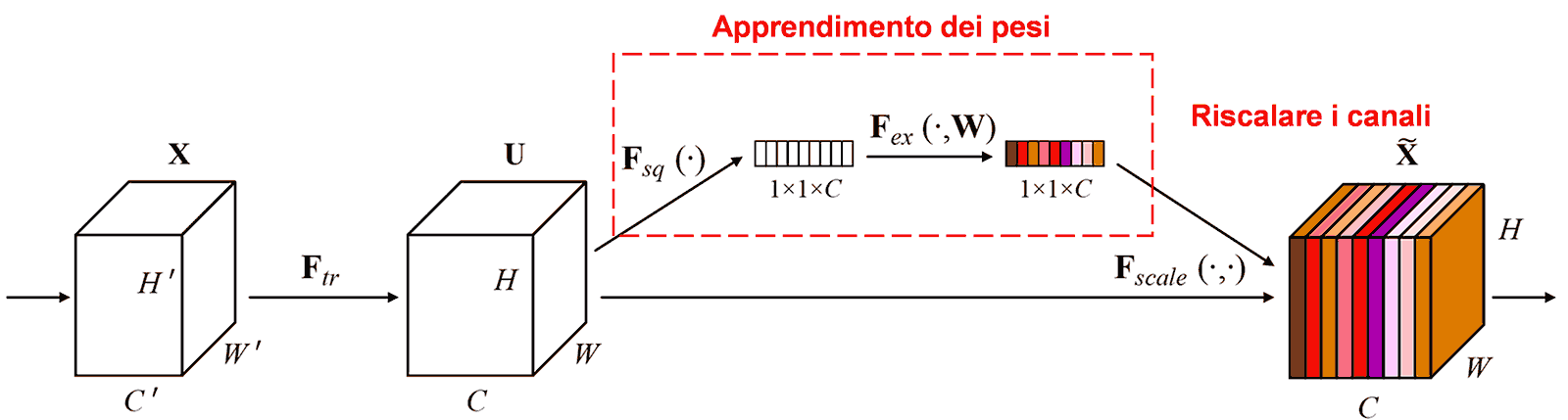
In questo modo, ogni campione ha il proprio set indipendente di pesi. Nella SENet, il percorso per ottenere i pesi è: “Global Pooling → Fully Connected Layer → ReLU → Fully Connected Layer → Sigmoid”.
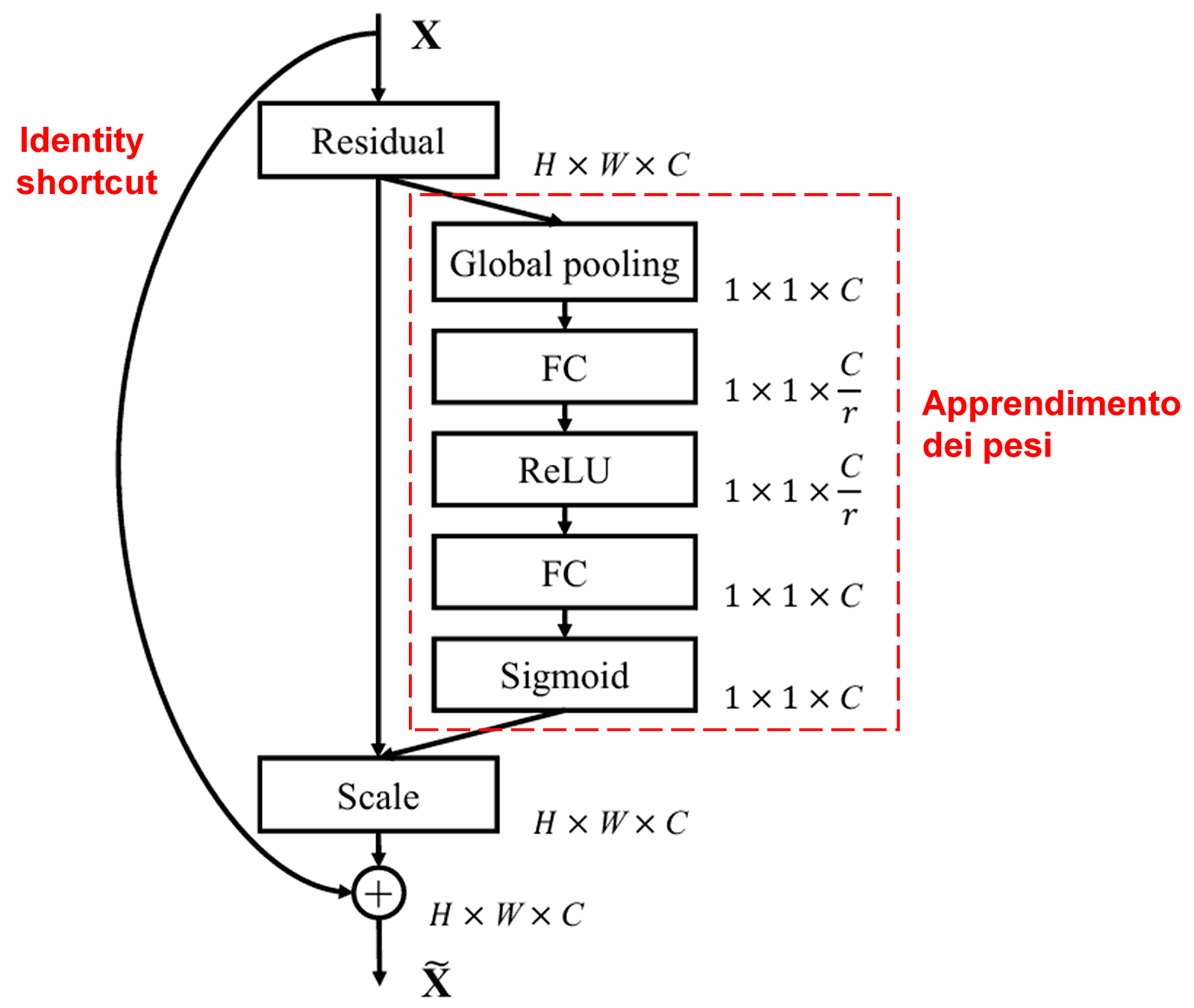
4. Soft Thresholding basato sul Meccanismo di Attenzione
La Deep Residual Shrinkage Network adotta la struttura della sottorete SENet per realizzare un Soft Thresholding guidato da un meccanismo di attenzione. Attraverso la sottorete (nel riquadro rosso), la rete apprende un set di soglie per applicare il Soft Thresholding ai vari canali delle feature.
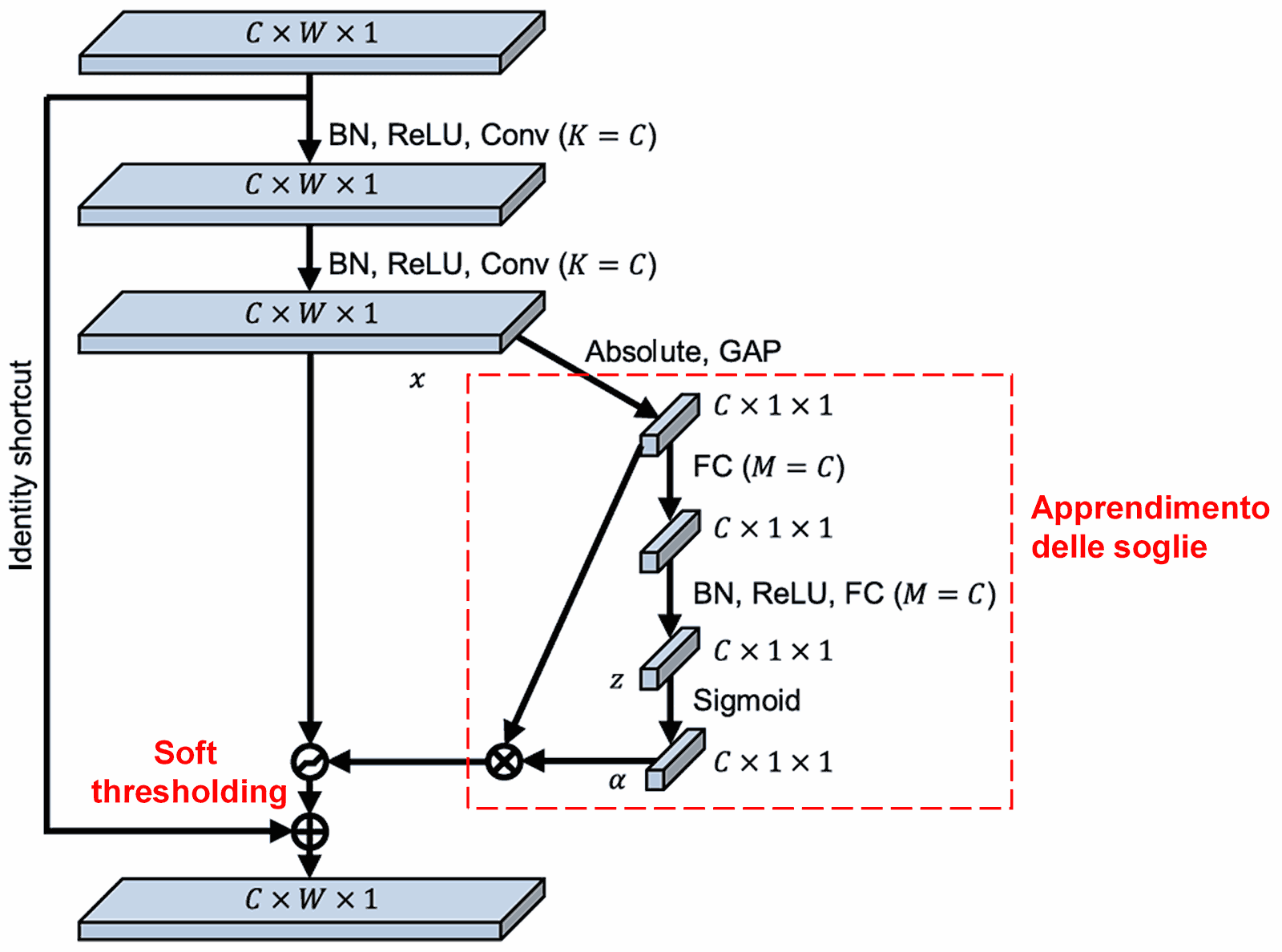
In questa sottorete, si calcola prima il valore assoluto di tutte le feature nella feature map di input. Successivamente, tramite Global Average Pooling, si ottiene una feature scalare, indicata come A. In parallelo, la feature map post-pooling entra in una piccola rete Fully Connected. L’ultimo strato di questa rete usa una Sigmoide per normalizzare l’uscita tra 0 e 1, ottenendo un coefficiente α. La soglia finale è α×A. Quindi, la soglia è un numero tra 0 e 1 moltiplicato per la media dei valori assoluti della feature map. Questo metodo garantisce che la soglia sia positiva e non eccessivamente grande.
Inoltre, campioni diversi avranno soglie diverse. Questo può essere inteso come un meccanismo di attenzione specializzato: la rete individua le feature irrilevanti, le trasforma in valori vicini allo 0 tramite strati convoluzionali e le azzera definitivamente con il Soft Thresholding; viceversa, individua le feature rilevanti e le preserva.
Infine, impilando questi moduli base insieme a strati convoluzionali, Batch Normalization, funzioni di attivazione, Global Average Pooling e strati di output Fully Connected, si ottiene la Deep Residual Shrinkage Network completa.
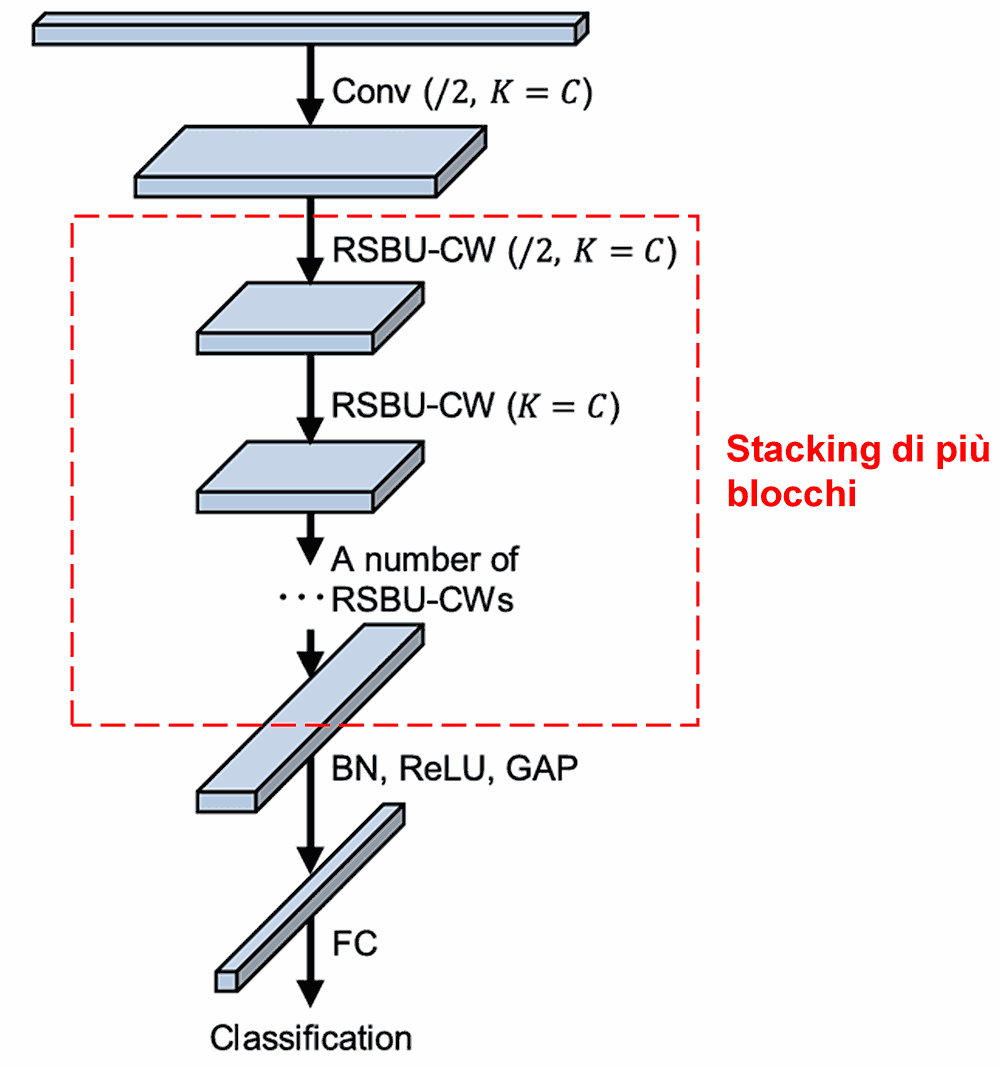
5. Capacità di Generalizzazione
La Deep Residual Shrinkage Network è, di fatto, un metodo di feature learning universale. In molti task, i campioni contengono rumore o informazioni non pertinenti che influenzano l’apprendimento. Ad esempio:
Nella classificazione di immagini, se un’immagine contiene molti oggetti estranei, questi agiscono da “rumore”; la DRSN può sfruttare il meccanismo di attenzione per rilevare questo “rumore” e, tramite Soft Thresholding, azzerare le feature corrispondenti, migliorando l’accuratezza.
Nel riconoscimento vocale in ambienti rumorosi (strade, fabbriche), la DRSN può migliorare l’accuratezza o fornire una metodologia valida per ottenerla.
Bibliografia
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Impatto Accademico
Le citazioni su Google Scholar hanno superato quota 1400.
Secondo stime prudenti, la Deep Residual Shrinkage Network è stata applicata (direttamente o con miglioramenti) in oltre 1000 pubblicazioni in settori quali ingegneria meccanica, ingegneria elettrica, computer vision, medicina, elaborazione vocale e del testo, radar e telerilevamento.