Das Deep Residual Shrinkage Network (DRSN) ist eine Weiterentwicklung des Deep Residual Networks (ResNet). Es handelt sich im Wesentlichen um eine Kombination aus ResNet, Attention-Mechanismen und Soft Thresholding.
Das Funktionsprinzip des DRSN lässt sich folgendermaßen zusammenfassen: Über einen Attention-Mechanismus werden unwichtige Features identifiziert und durch Soft Thresholding eliminiert (auf Null gesetzt); wichtige Features hingegen werden erkannt und beibehalten. Dies stärkt die Fähigkeit des tiefen neuronalen Netzes, nützliche Features aus verrauschten Signalen zu extrahieren.
1. Motivation
Erstens sind Samples bei der Klassifikation unvermeidlich mit Rauschen behaftet, wie z.B. Gaußsches Rauschen, Rosa Rauschen oder Laplace-Rauschen. Im weiteren Sinne enthalten Samples oft Informationen, die für die aktuelle Aufgabe irrelevant sind und somit ebenfalls als Rauschen betrachtet werden können. Dieses Rauschen kann die Performance beeinträchtigen. (Soft Thresholding ist ein entscheidender Schritt in vielen Algorithmen zur Signalentstörung).
Ein Beispiel: Bei einem Gespräch am Straßenrand überlagern sich Sprachsignale mit Autohupen und Reifengeräuschen. Bei der Spracherkennung wird das Ergebnis durch diese Störgeräusche beeinträchtigt. Aus Sicht des Deep Learning sollten die Features, die diesen Geräuschen entsprechen, innerhalb des Netzes eliminiert werden, um die Spracherkennung nicht zu verfälschen.
Zweitens variiert der Rauschanteil oft von Sample zu Sample, selbst innerhalb desselben Datensatzes. (Dies ähnelt dem Attention-Mechanismus: In einem Bilddatensatz variiert die Position des Zielobjekts; Attention fokussiert sich auf die relevante Stelle in jedem einzelnen Bild).
Beispiel: Beim Training eines Klassifikators für Katzen und Hunde könnten fünf Bilder mit dem Label „Hund“ ganz unterschiedliche Störobjekte enthalten (Maus, Gans, Huhn, Esel, Ente). Diese irrelevanten Objekte stören das Training und senken die Accuracy. Wenn das Netzwerk diese irrelevanten Objekte bemerkt und ihre korrespondierenden Features entfernt, kann die Genauigkeit des Klassifikators verbessert werden.
2. Soft Thresholding
Soft Thresholding ist ein Kernschritt vieler Signalentstörungs-Algorithmen. Dabei werden Features, deren Absolutbetrag unter einem bestimmten Schwellenwert (Threshold) liegt, auf Null gesetzt, und Features, die darüber liegen, in Richtung Null „geschrumpft“. Die Formel lautet:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Die Ableitung des Soft Thresholding bezüglich des Inputs ist:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Die Ableitung ist also entweder 1 oder 0. Diese Eigenschaft ist identisch mit der ReLU-Aktivierungsfunktion. Daher kann Soft Thresholding auch das Risiko von Gradient Vanishing und Gradient Exploding verringern.
Für den Schwellenwert gelten zwei Bedingungen: Erstens muss er positiv sein; zweitens darf er nicht größer als der Maximalwert des Input-Signals sein, da der Output sonst komplett Null wäre.
Idealerweise sollte eine dritte Bedingung erfüllt sein: Jedes Sample sollte abhängig von seinem Rauschanteil einen eigenen, unabhängigen Schwellenwert haben.
Denn Sample A kann wenig Rauschen enthalten (kleiner Schwellenwert nötig), während Sample B viel Rauschen enthält (großer Schwellenwert nötig). Auch wenn Features und Schwellenwerte im neuronalen Netz ihre explizite physikalische Bedeutung verlieren, bleibt das Prinzip gleich: Der Schwellenwert muss sich dynamisch an das Sample anpassen.
3. Attention-Mechanismus
Attention-Mechanismen sind im Bereich Computer Vision intuitiv verständlich. Das visuelle System von Tieren scannt einen Bereich, entdeckt ein Zielobjekt und fokussiert die Aufmerksamkeit darauf, um Details zu extrahieren und Irrelevantes zu unterdrücken.
Das Squeeze-and-Excitation Network (SENet) ist eine bekannte Methode basierend auf Attention. Die Relevanz verschiedener Feature Channels variiert oft je nach Sample. SENet nutzt ein kleines Sub-Netzwerk, um Gewichte (Weights) zu lernen, und multipliziert diese mit den Features der Kanäle, um deren Intensität zu skalieren.
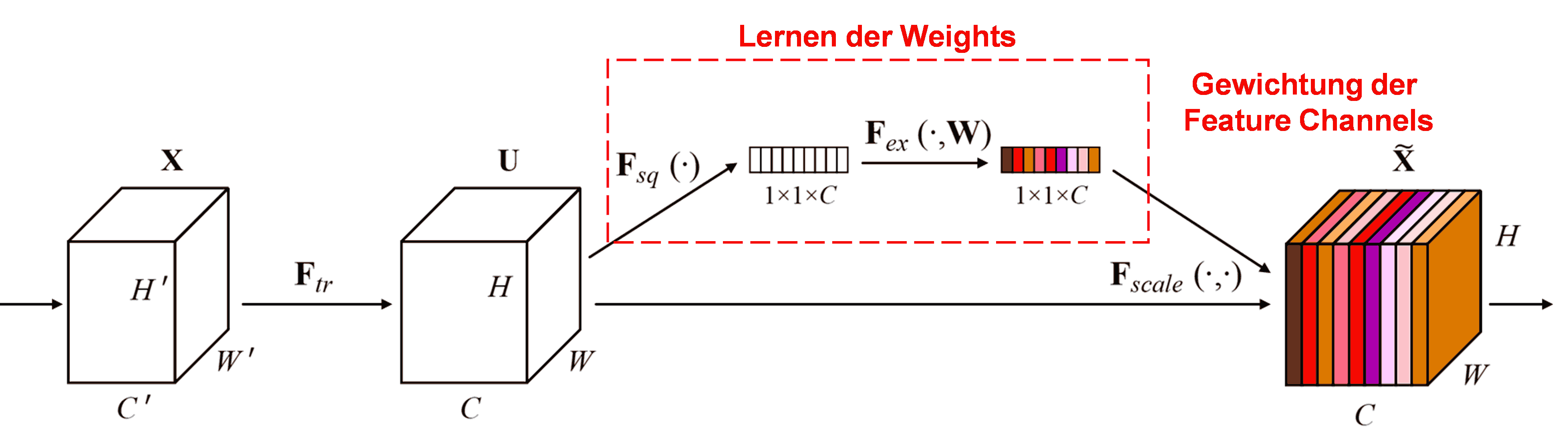
Dabei hat jedes Sample seinen eigenen Satz von Gewichten. Im SENet ist der Pfad zur Berechnung: „Global Pooling → Fully Connected Layer → ReLU → Fully Connected Layer → Sigmoid“.
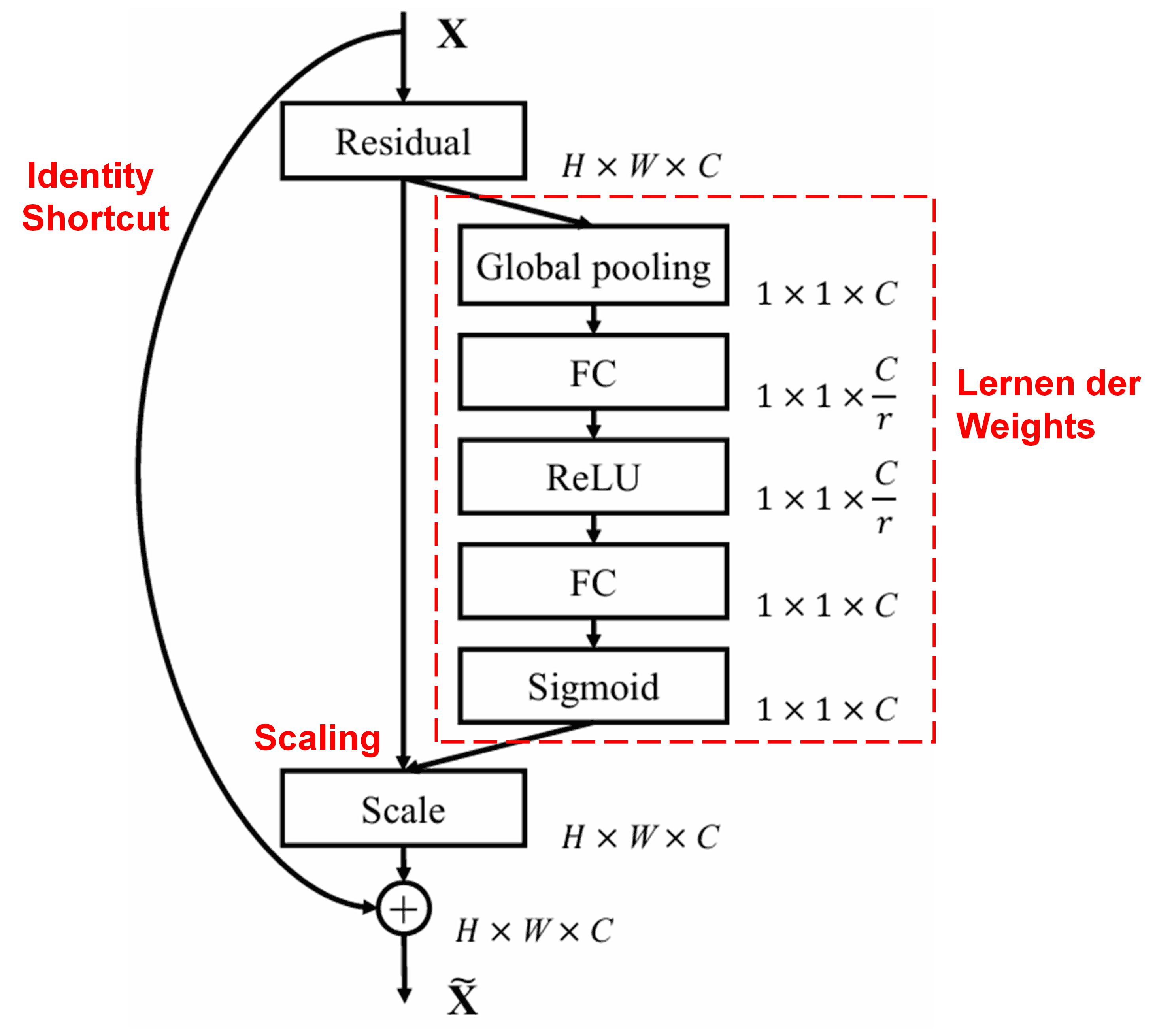
4. Soft Thresholding mit Deep Attention Mechanism
Das Deep Residual Shrinkage Network nutzt die Struktur des SENet-Sub-Netzwerks, um Soft Thresholding in einer Deep-Learning-Architektur zu realisieren. Durch das (in den Diagrammen rot markierte) Sub-Netzwerk wird ein Satz von Schwellenwerten gelernt, um die Feature Channels individuell zu filtern.
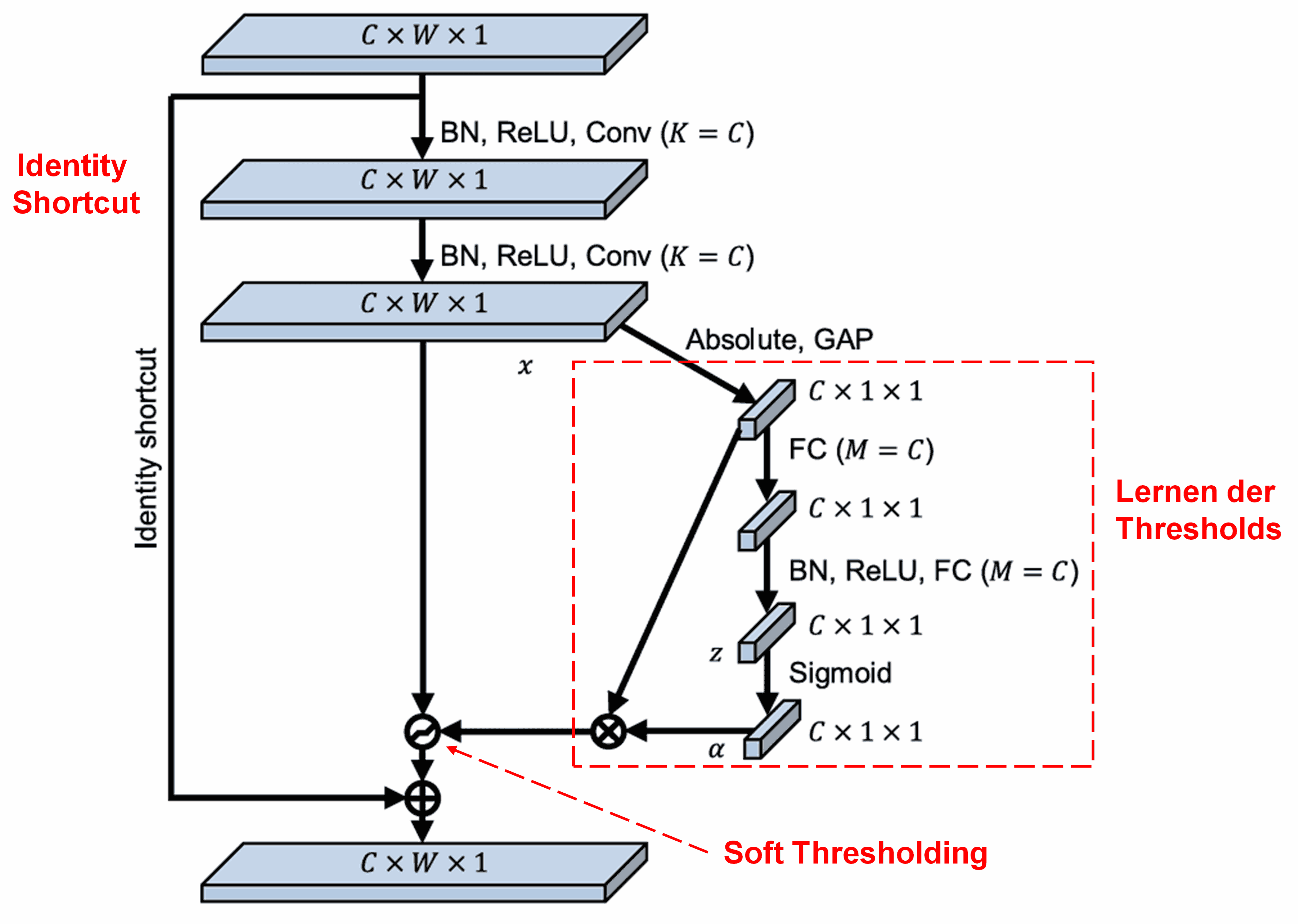
In diesem Sub-Netzwerk werden die Absolutwerte der Eingabe-Feature Map berechnet. Über Global Average Pooling erhält man einen Wert A. Parallel dazu wird die Feature Map in ein kleines Fully Connected Network geleitet, das (mit einer Sigmoid-Funktion am Ende) einen Koeffizienten α zwischen 0 und 1 ausgibt. Der Schwellenwert berechnet sich aus α · A. Dies garantiert, dass der Schwellenwert positiv ist und nicht zu groß wird.
Da verschiedene Samples verschiedene Schwellenwerte erhalten, fungiert dies als spezieller Attention-Mechanismus: Irrelevante Features werden erkannt, durch zwei Convolutional Layers auf Werte nahe 0 gebracht und via Soft Thresholding eliminiert. Relevante Features werden auf Werte fern von 0 gebracht und beibehalten.
Das komplette Netzwerk besteht aus einer Stapelung dieser Basismodule sowie Convolutional Layers, Batch Normalization, Aktivierungsfunktionen, Global Average Pooling und einem Fully Connected Output Layer.
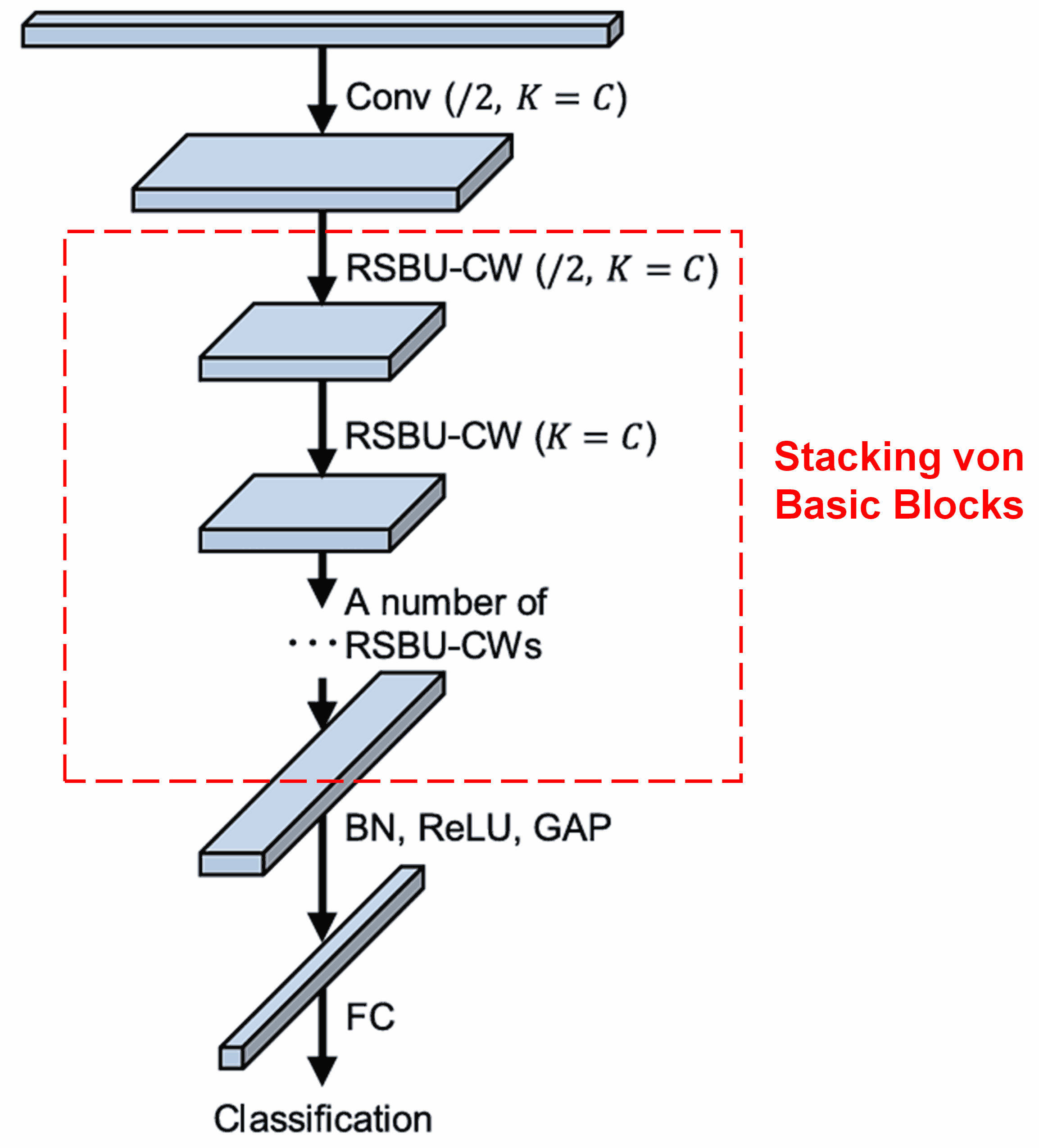
5. Generalisierungsfähigkeit
Das DRSN ist eine universelle Methode für Feature Learning, da viele Aufgaben verrauschte Daten beinhalten.
Bei der Bildklassifikation: Wenn ein Bild viele irrelevante Objekte („Rauschen“) enthält, kann das DRSN diese über den Attention-Mechanismus erkennen und die entsprechenden Features per Soft Thresholding eliminieren, was die Genauigkeit erhöht.
Bei der Spracherkennung: In lauten Umgebungen (Fabrik, Straße) kann das DRSN helfen, die Erkennungsrate zu verbessern, oder zumindest einen Ansatz dafür liefern.
Literaturverzeichnis
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Impact
Die Arbeit wurde auf Google Scholar bereits über 1400 Mal zitiert.
Laut unvollständigen Statistiken wurde das Deep Residual Shrinkage Network in über 1000 Publikationen direkt angewendet oder weiterentwickelt, unter anderem in den Bereichen Maschinenbau, Energiewirtschaft, Computer Vision, Medizin, Sprachverarbeitung, Radar und Fernerkundung.