Deep Residual Shrinkage Network हे Deep Residual Network (ResNet) चेच एक सुधारित व्हर्जन (improved version) आहे. सोप्या भाषेत सांगायचे तर, हे Deep Residual Network, Attention Mechanism आणि Soft Thresholding फंक्शनचे एकत्रीकरण (integration) आहे.
काही प्रमाणात, Deep Residual Shrinkage Network चे काम करण्याची पद्धत (working principle) आपण अशी समजू शकतो: हे नेटवर्क Attention Mechanism द्वारे महत्वाचे नसलेले (unimportant) फीचर्स ओळखते आणि Soft Thresholding फंक्शन वापरून त्यांना ‘झिरो’ (zero) सेट करते. किंवा असे म्हणू शकतो की, हे नेटवर्क महत्वाचे फीचर्स लक्षात घेते आणि त्यांना राखून ठेवते (retain करते). यामुळे Noise असलेल्या सिग्नलमधून उपयुक्त फीचर्स शोधून काढण्याची Deep Neural Network ची क्षमता वाढते.
1. Research Motivation (संशोधनांमागचा उद्देश)
सर्वात आधी, सॅम्पल्सचे वर्गीकरण (classification) करताना, त्यामध्ये Noise असणे अपरिहार्य आहे, जसे की Gaussian noise, Pink noise, Laplacian noise इत्यादी. अधिक व्यापक अर्थाने, सॅम्पल्समध्ये बऱ्याचदा अशी माहिती असते जी सध्याच्या क्लासिफिकेशन टास्कसाठी कामाची नसते; यालाही आपण ‘Noise’ समजू शकतो. हा नॉईज क्लासिफिकेशनच्या रिझल्टवर वाईट परिणाम करू शकतो. (Soft Thresholding ही अनेक सिग्नल डी-नॉईजिंग (signal denoising) अल्गोरिदममधील एक महत्त्वाची स्टेप आहे.)
उदाहरणादाखल, रस्त्याच्या कडेला गप्पा मारताना, आवाजाच्या सिग्नलमध्ये वाहनांचे हॉर्न, चाकांचा आवाज इत्यादी मिसळलेले असू शकतात. जेव्हा आपण अशा सिग्नलवर Speech Recognition करतो, तेव्हा या बॅकग्राउंड आवाजांचा (Noise) नक्कीच परिणाम होतो. Deep Learning च्या दृष्टिकोनातून, हॉर्न आणि चाकांच्या आवाजाशी संबंधित फीचर्स Deep Neural Network मध्ये काढून टाकले (delete) पाहिजेत, जेणेकरून Speech Recognition च्या अचूकतेवर परिणाम होणार नाही.
दुसरी गोष्ट म्हणजे, एकाच डेटासेटमध्ये (Dataset) सुद्धा, प्रत्येक सॅम्पलमधील नॉईजचे प्रमाण (Noise level) हे वेगवेगळे असू शकते. (हे Attention Mechanism सारखेच आहे; एका इमेज डेटासेटचे उदाहरण घेतल्यास, प्रत्येक इमेजमध्ये टार्गेट ऑब्जेक्टची जागा वेगवेगळी असू शकते; Attention Mechanism प्रत्येक इमेजसाठी टार्गेट ऑब्जेक्टच्या जागेवर लक्ष केंद्रित करू शकते).
उदाहरणार्थ, जेव्हा आपण ‘Cat-Dog Classifier’ ट्रेन करतो, तेव्हा ‘Dog’ (कुत्रा) असे लेबल असलेल्या 5 इमेजेसचा विचार करा. पहिल्या इमेजमध्ये कुत्र्यासोबत उंदीर असू शकतो, दुसऱ्या इमेजमध्ये कुत्र्यासोबत बदक असू शकते, तिसऱ्यात कोंबडी, चौथ्यात गाढव, आणि पाचव्या इमेजमध्ये कुत्र्यासोबत हंस असू शकतो. आपण जेव्हा मॉडेल ट्रेन करतो, तेव्हा उंदीर, बदक, कोंबडी, गाढव आणि हंस यांसारख्या अनावश्यक गोष्टींचा (irrelevant objects) अडथळा निर्माण होतो, ज्यामुळे क्लासिफिकेशनची Accuracy कमी होऊ शकते. जर आपण या अनावश्यक गोष्टींकडे लक्ष देऊन त्यांच्याशी संबंधित फीचर्स काढून टाकले, तर ‘Cat-Dog Classifier’ ची ॲक्युरसी वाढण्याची शक्यता असते.
2. Soft Thresholding (सॉफ्ट थ्रेशोल्डिंग)
Soft Thresholding ही अनेक सिग्नल डी-नॉईजिंग अल्गोरिदमची कोअर स्टेप (core step) आहे. यामध्ये, एका ठराविक Threshold पेक्षा ज्या फीचर्सची Absolute Value कमी आहे, त्यांना काढून टाकले जाते (set to zero). आणि ज्या फीचर्सची Absolute Value या Threshold पेक्षा जास्त आहे, त्यांना ‘झिरो’ च्या दिशेने ‘shrink’ (संकुचित) केले जाते. हे खालील फॉर्म्युला वापरून केले जाते:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]इनपुटच्या संदर्भात Soft Thresholding आउटपुटचा डेरिव्हेटिव्ह (Derivative) खालीलप्रमाणे आहे:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]वर पाहिल्याप्रमाणे, Soft Thresholding चा डेरिव्हेटिव्ह एकतर 1 असतो किंवा 0 असतो. हा गुणधर्म ReLU Activation Function सारखाच आहे. त्यामुळे, Soft Thresholding मुळे Deep Learning अल्गोरिदममध्ये Gradient Vanishing आणि Gradient Exploding चा धोका कमी होण्यास मदत होते.
Soft Thresholding फंक्शनमध्ये, Threshold सेट करताना दोन अटींचे (conditions) पालन करणे आवश्यक आहे: पहिली अट म्हणजे Threshold हा पॉझिटिव्ह (positive) नंबर असावा; दुसरी अट म्हणजे Threshold हा इनपुट सिग्नलच्या मॅक्सिमम व्हॅल्यू (maximum value) पेक्षा मोठा नसावा, नाहीतर आउटपुट पूर्णपणे झिरो होईल.
त्याचबरोबर, Threshold ने तिसऱ्या अटीचे पालन करणे सुद्धा फायद्याचे ठरते: प्रत्येक सॅम्पलला त्याच्या स्वतःच्या नॉईज प्रमाणानुसार (noise content) स्वतंत्र Threshold असावा.
याचे कारण असे की, अनेक सॅम्पल्समध्ये नॉईजचे प्रमाण वेगवेगळे असते. उदाहरणार्थ, एकाच डेटासेटमध्ये सॅम्पल A मध्ये कमी नॉईज असू शकतो आणि सॅम्पल B मध्ये जास्त नॉईज असू शकतो. अशा वेळी, डी-नॉईजिंग अल्गोरिदममध्ये Soft Thresholding वापरताना, सॅम्पल A साठी छोटा Threshold आणि सॅम्पल B साठी मोठा Threshold वापरला पाहिजे. Deep Neural Network मध्ये जरी या फीचर्स आणि थ्रेशोल्डचा थेट भौतिक अर्थ (physical meaning) स्पष्ट नसला, तरी मूळ लॉजिक तेच राहते. म्हणजेच, प्रत्येक सॅम्पलला त्याच्या नॉईज लेवलनुसार स्वतःचा स्वतंत्र Threshold असावा.
3. Attention Mechanism (अटेन्शन मेकॅनिझम)
Computer Vision क्षेत्रात Attention Mechanism समजणे तुलनेने सोपे आहे. प्राण्यांची व्हिज्युअल सिस्टीम (visual system) वेगाने पूर्ण भाग स्कॅन करून टार्गेट वस्तू शोधते आणि नंतर फक्त त्या टार्गेटवर लक्ष केंद्रित (focus) करते, जेणेकरून जास्त डिटेल्स मिळवता येतील आणि अनावश्यक माहितीकडे दुर्लक्ष करता येईल. अधिक माहितीसाठी कृपया Attention Mechanism वरील साहित्याचा संदर्भ घ्यावा.
Squeeze-and-Excitation Network (SENet) ही Attention Mechanism वापरणारी एक नवीन Deep Learning पद्धत आहे. वेगवेगळ्या सॅम्पल्समध्ये, क्लासिफिकेशन टास्कसाठी वेगवेगळ्या फीचर चॅनल्सचे (Feature Channels) योगदान (contribution) वेगवेगळे असते. SENet एक छोटे सब-नेटवर्क (sub-network) वापरून वेट्सचा (weights) एक संच मिळवते. त्यानंतर हे वेट्स आणि त्या-त्या चॅनेलचे फीचर्स यांचा गुणाकार केला जातो. या प्रोसेसमुळे प्रत्येक चॅनेलच्या फीचर्सची तीव्रता ॲडजस्ट केली जाते. यालाच आपण वेगवेगळ्या फीचर चॅनल्सवर वेगवेगळ्या प्रमाणात ‘Attention’ देणे असे म्हणू शकतो.
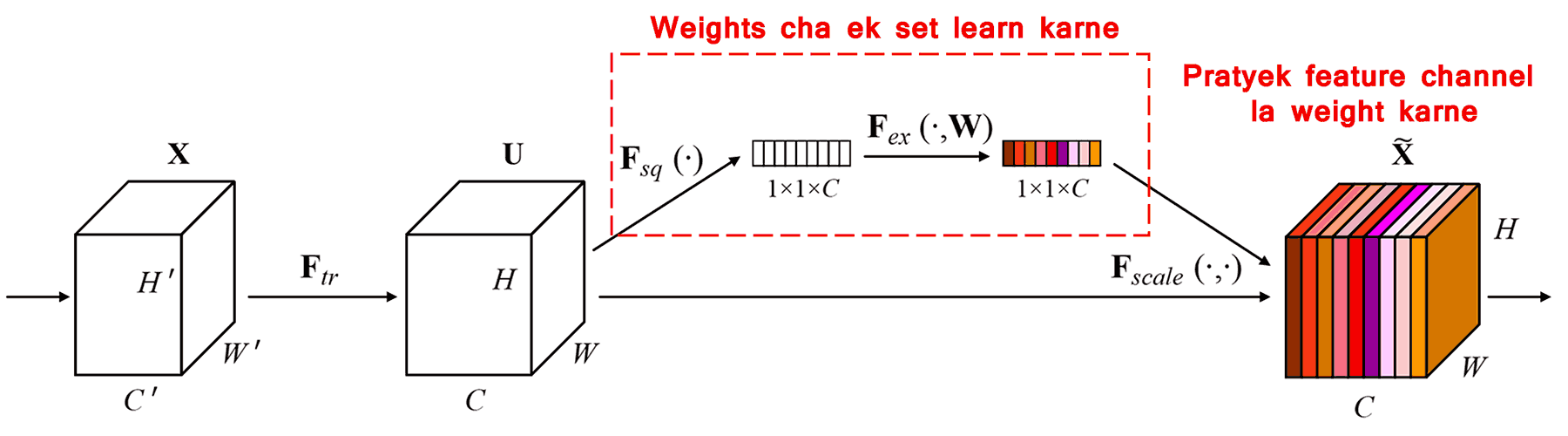
या पद्धतीत, प्रत्येक सॅम्पलसाठी वेट्सचा (weights) सेट स्वतंत्र असतो. दुसऱ्या शब्दांत, कोणत्याही दोन सॅम्पल्सचे वेट्स वेगळे असतात. SENet मध्ये, वेट्स मिळवण्याचा मार्ग “Global Pooling → Fully Connected Layer → ReLU Function → Fully Connected Layer → Sigmoid Function” असा असतो.
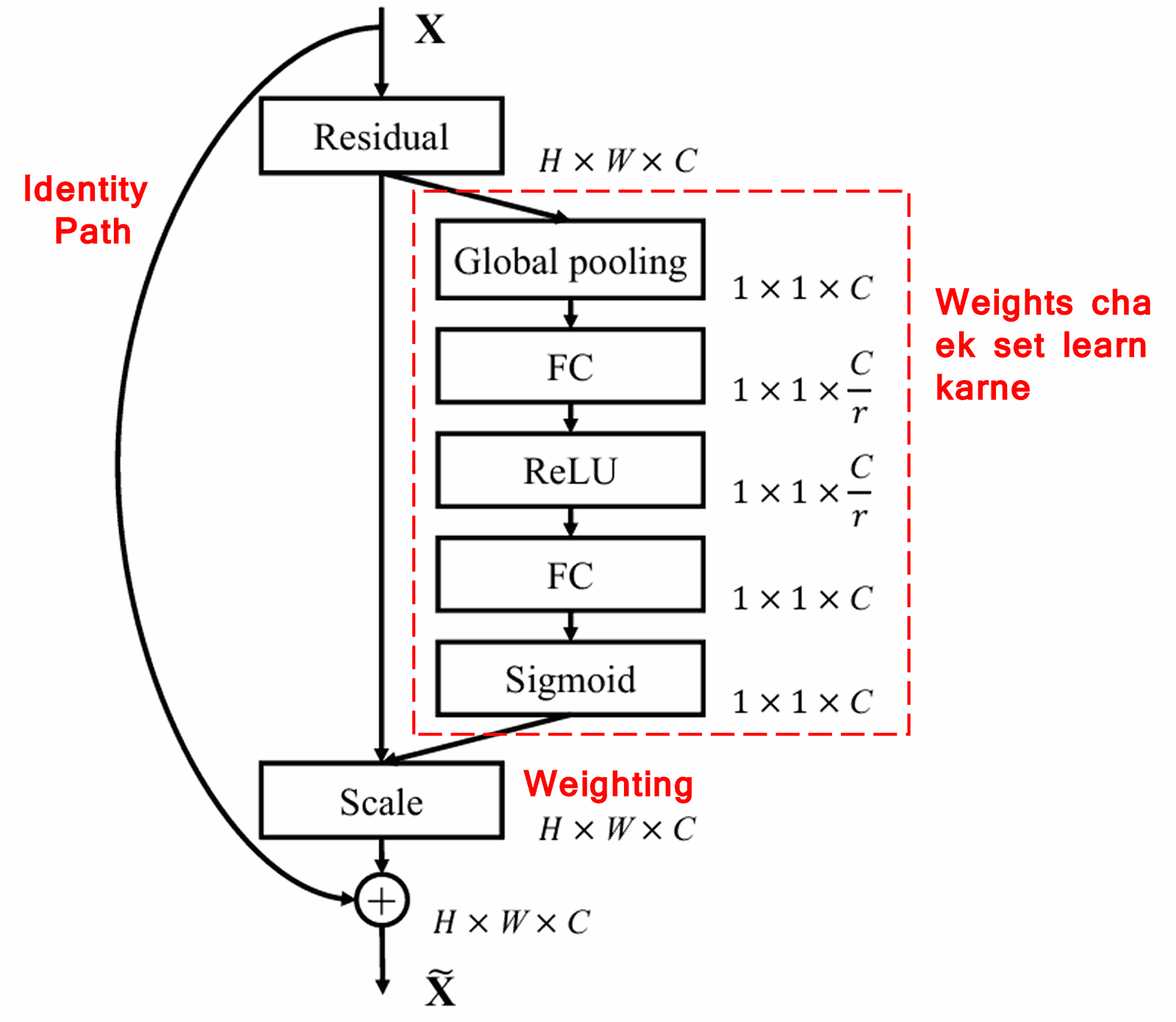
4. Soft Thresholding with Deep Attention Mechanism
Deep Residual Shrinkage Network ने वर नमूद केलेल्या SENet च्या सब-नेटवर्क स्ट्रक्चरचा आधार घेतला आहे, ज्यायोगे Deep Attention Mechanism अंतर्गत Soft Thresholding करता येईल. लाल चौकटीत (Red box) दर्शविलेल्या सब-नेटवर्कद्वारे, एक Threshold चा संच शिकला (learn) जातो, जो प्रत्येक फीचर चॅनेलवर Soft Thresholding लागू करतो.
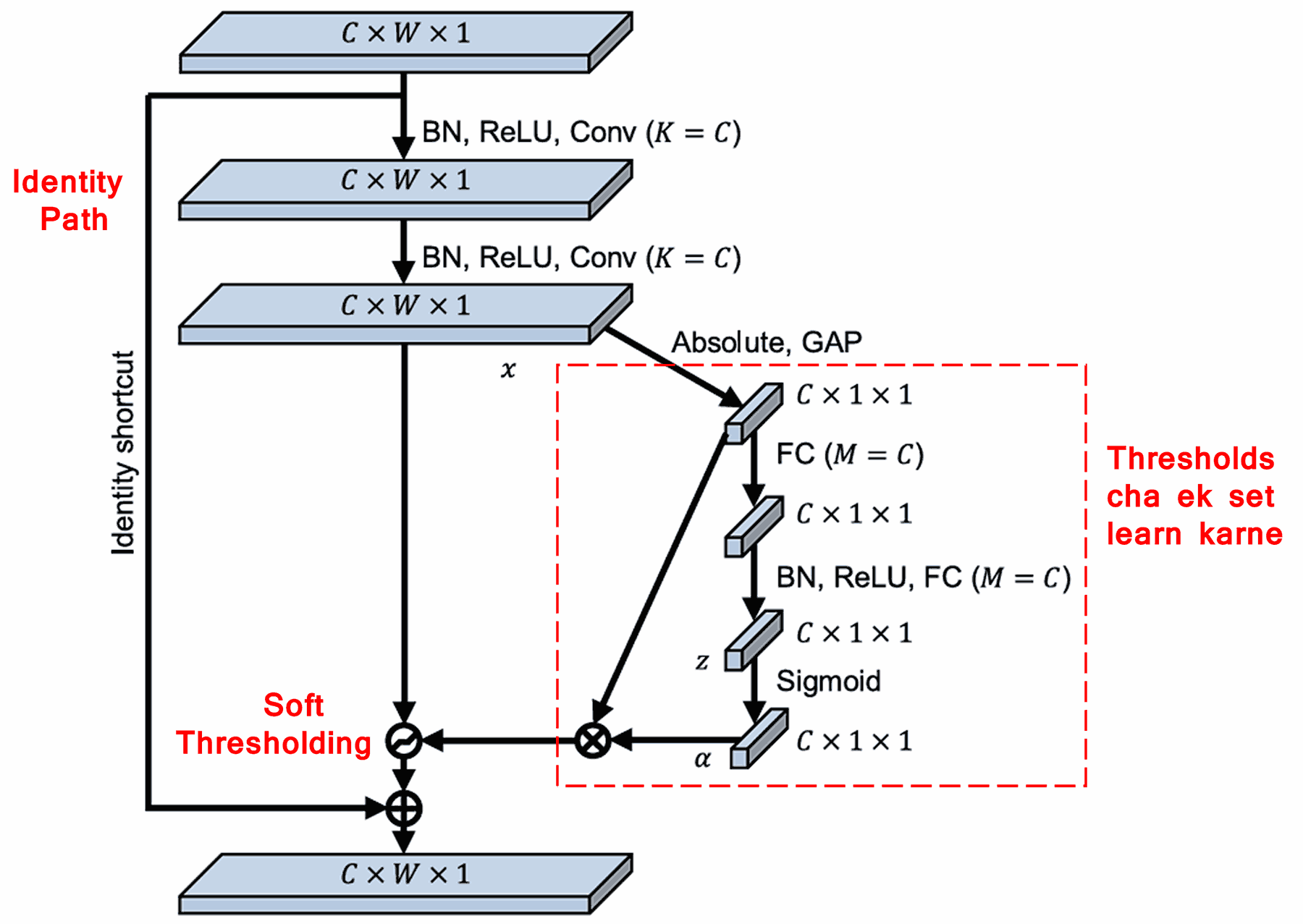
या सब-नेटवर्कमध्ये, सर्वप्रथम इनपुट फीचर मॅपच्या सर्व फीचर्सची Absolute Value काढली जाते. त्यानंतर Global Average Pooling आणि ॲव्हरेजिंग (averaging) करून एक फीचर मिळवला जातो, ज्याला आपण A समजू. दुसऱ्या बाजूला, Global Average Pooling नंतरच्या फीचर मॅपला एका लहान Fully Connected Network मध्ये इनपुट दिले जाते. या Fully Connected Network च्या शेवटच्या लेयरमध्ये Sigmoid Function वापरले जाते, जे आउटपुटला 0 आणि 1 च्या दरम्यान आणते (normalize करते). यातून मिळणाऱ्या कोफिशियंटला (coefficient) आपण α समजू. फायनल Threshold हा α × A म्हणून दर्शविला जातो. म्हणजेच, Threshold हा 0 ते 1 मधील एक संख्या आणि फीचर मॅपच्या Absolute Values ची सरासरी यांचा गुणाकार आहे. ही पद्धत हे सुनिश्चित करते की Threshold पॉझिटिव्ह (positive) आहे आणि तो खूप मोठा (too large) सुद्धा नाही.
तसेच, यामुळे वेगवेगळ्या सॅम्पल्ससाठी वेगवेगळे Thresholds मिळतात. त्यामुळे, काही प्रमाणात याला एक विशेष प्रकारची Attention Mechanism समजले जाऊ शकते: हे नेटवर्क सध्याच्या टास्कशी संबंधित नसलेले फीचर्स (unrelated features) ओळखते, दोन कॉन्व्होल्युशनल लेयर्स (Convolutional Layers) द्वारे त्यांना 0 च्या जवळ आणते, आणि Soft Thresholding वापरून त्यांना पूर्णपणे झिरो (zero) करते. किंवा, टास्कशी संबंधित महत्त्वाचे फीचर्स ओळखून त्यांना 0 पासून दूर ठेवते आणि जतन (preserve) करते.
शेवटी, काही बेसिक मॉड्यूल्स (basic modules), कॉन्व्होल्युशनल लेयर्स, Batch Normalization, Activation Functions, Global Average Pooling आणि Fully Connected Output Layers यांना एकमेकांवर स्टॅक (stack) करून पूर्ण Deep Residual Shrinkage Network तयार होते.
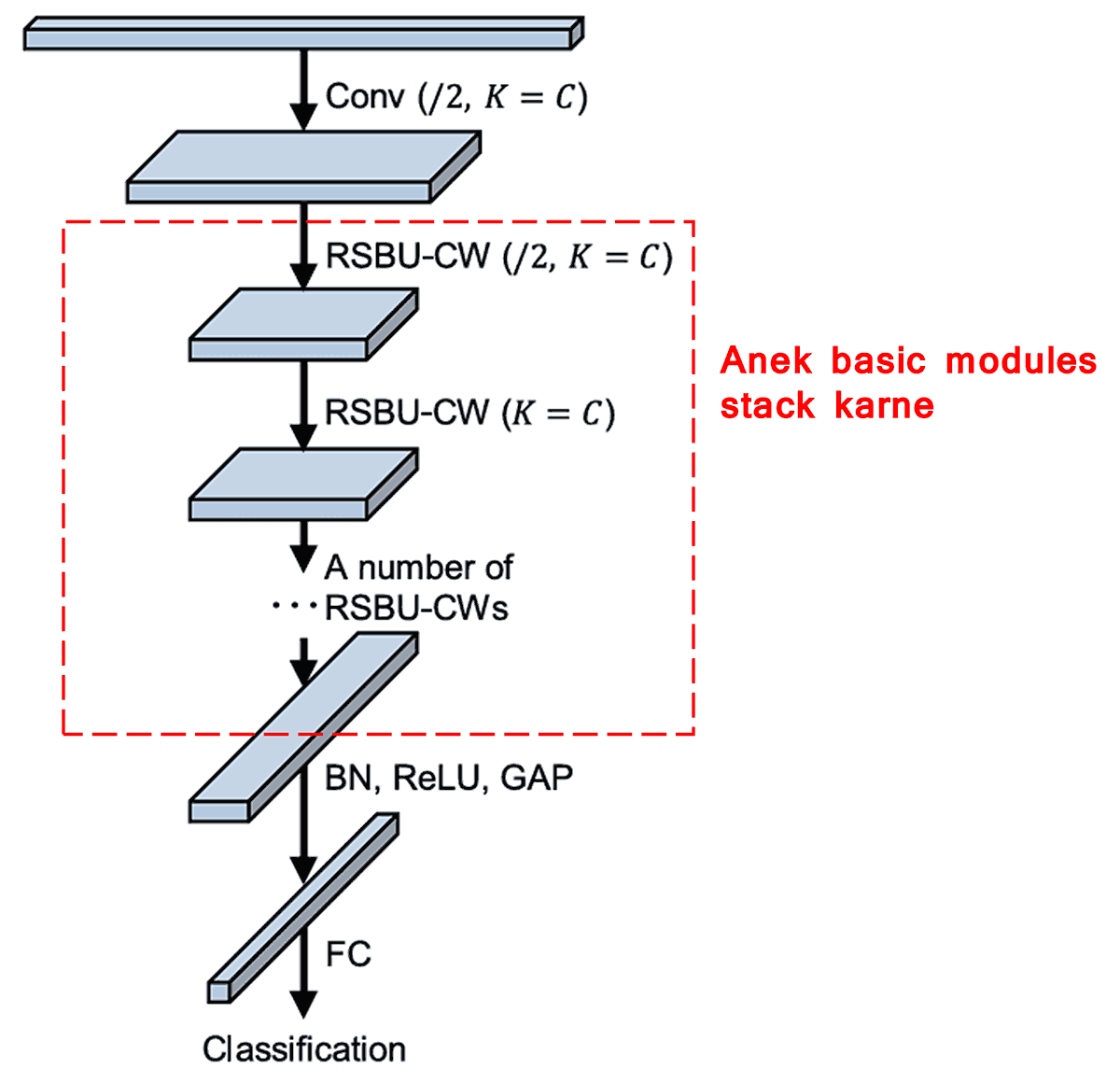
5. Generalization Capability (सामान्यउपयोगिता)
Deep Residual Shrinkage Network ही वास्तविकपणे एक जनरल फीचर लर्निंग मेथड (general feature learning method) आहे. कारण अनेक फीचर लर्निंग टास्कमध्ये, सॅम्पल्समध्ये कमी-अधिक प्रमाणात नॉईज किंवा अनावश्यक माहिती असतेच. हा नॉईज आणि अनावश्यक माहिती फीचर लर्निंगच्या निकालावर परिणाम करू शकते. उदाहरणार्थ:
Image Classification मध्ये, जर इमेजमध्ये इतर अनेक वस्तू असतील, तर त्यांना “Noise” समजले जाऊ शकते. Deep Residual Shrinkage Network कदाचित Attention Mechanism वापरून या “Noise” कडे लक्ष देऊ शकते आणि Soft Thresholding द्वारे या “Noise” शी संबंधित फीचर्सना झिरो सेट करू शकते. यामुळे इमेज क्लासिफिकेशनची ॲक्युरसी वाढण्याची शक्यता आहे.
Speech Recognition मध्ये, जर वातावरण खूप गोंगाटाचे (noisy) असेल, उदाहरणार्थ रस्त्याच्या कडेला किंवा फॅक्टरीमध्ये बोलताना, तेव्हा Deep Residual Shrinkage Network कदाचित स्पीच रेकग्निशनची ॲक्युरसी वाढवू शकते, किंवा ॲक्युरसी वाढवण्यासाठी एक नवीन दृष्टीकोन (approach) देऊ शकते.
Reference (संदर्भ)
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Academic Impact (शैक्षणिक प्रभाव)
या पेपरला Google Scholar वर 1400 पेक्षा जास्त वेळा साईट (cite) करण्यात आले आहे.
अपूर्ण आकडेवारीनुसार, Deep Residual Shrinkage Network (DRSN) चा वापर किंवा सुधारणा 1000 पेक्षा जास्त शोधनिबंधांमध्ये (publications) करण्यात आली आहे. यामध्ये मेकॅनिकल, इलेक्ट्रिक पॉवर, कॉम्प्युटर व्हिजन, मेडिकल, स्पीच, टेक्स्ट, रडार आणि रिमोट सेन्सिंग यांसारख्या अनेक क्षेत्रांचा समावेश आहे.