深度殘差收縮網路是深度殘差網路的一種改良版本,實際上是深度殘差網路、注意力機制與軟閾值函數的整合。
在一定程度上,深度殘差收縮網路的工作原理,可以理解為:透過注意力機制注意到不重要的特徵,透過軟閾值函數將它們置為零;換句話說,透過注意力機制注意到重要的特徵,將它們保留下來,從而加強深度神經網路從含雜訊訊號中提取有用特徵的能力。
1. 研究動機
首先,在對樣本進行分類的時候,樣本中難免會有一些雜訊,像是高斯雜訊、粉紅雜訊、拉普拉斯雜訊等。更廣義地講,樣本中很有可能包含著與當前分類任務無關的資訊,這些資訊也可以理解為雜訊。這些雜訊可能會對分類效果產生不利的影響。(軟閾值化是許多訊號降噪演算法中的一個關鍵步驟)
舉例來說,在馬路邊聊天的時候,聊天的聲音裡就可能會混雜車輛的喇叭聲、輪胎聲等等。當對這些聲音訊號進行語音辨識的時候,辨識效果不可避免地會受到喇叭聲、輪胎聲的影響。從深度學習的角度來講,這些喇叭聲、輪胎聲所對應的特徵,就應該在深度神經網路內部被刪除掉,以避免對語音辨識的效果造成影響。
其次,即使是同一個樣本集,各個樣本的雜訊量也往往是不同的。(這和注意力機制有相通之處;以一個影像樣本集為例,各張影像中目標物體所在的位置可能是不同的;注意力機制可以針對每一張影像,注意到目標物體所在的位置)
例如,當訓練貓狗分類器的時候,對於標籤為「狗」的5張影像,第1張影像可能同時包含著狗和老鼠,第2張影像可能同時包含著狗和鵝,第3張影像可能同時包含著狗和雞,第4張影像可能同時包含著狗和驢,第5張影像可能同時包含著狗和鴨子。我們在訓練貓狗分類器時,就難免會受到老鼠、鵝、雞、驢和鴨子等無關物體的干擾,造成分類準確率下降。如果我們能夠注意到這些無關的老鼠、鵝、雞、驢和鴨子,將它們所對應的特徵刪除掉,就有可能提高貓狗分類器的準確率。
2. 軟閾值化
軟閾值化,是很多訊號降噪演算法的核心步驟,將絕對值小於某個閾值(Threshold)的特徵刪除掉,將絕對值大於這個閾值的特徵朝著零的方向進行收縮。它可以透過以下公式來實現:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]軟閾值化的輸出對於輸入的導數為:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]由上可知,軟閾值化的導數不是1,就是0。這個性質是和ReLU激勵函數是相同的。因此,軟閾值化也能夠降低深度學習演算法遭遇梯度消失和梯度爆炸的風險。
在軟閾值化函數中,閾值的設定必須符合兩個條件:第一,閾值是正數;第二,閾值不能大於輸入訊號的最大值,否則輸出會全部為零。
同時,閾值最好還能符合第三個條件:每個樣本應該根據自身的雜訊含量,有著自己獨立的閾值。
這是因為,很多樣本的雜訊含量經常是不同的。例如經常會有這種情況,在同一個樣本集裡面,樣本A所含雜訊較少,樣本B所含雜訊較多。那麼,如果是在降噪演算法裡進行軟閾值化的時候,樣本A就應該採用較小的閾值,樣本B就應該採用較大的閾值。在深度神經網路中,雖然這些特徵和閾值失去了明確的物理意義,但是基本的道理還是相通的。也就是說,每個樣本應該根據自身的雜訊含量,有著自己獨立的閾值。
3. 注意力機制
注意力機制在電腦視覺領域是比較容易理解的。動物的視覺系統可以快速掃描全部區域,發現目標物體,進而將注意力集中在目標物體上,以提取更多的細節,同時抑制無關資訊。具體請參考注意力機制方面的文章。
Squeeze-and-Excitation Network(SENet)是一種較新的注意力機制下的深度學習方法。 在不同的樣本中,不同的特徵通道,在分類任務中的貢獻大小,往往是不同的。SENet採用一個小型子網路,獲得一組權重,進而將這組權重與各個通道的特徵分別相乘,以調整各個通道特徵的大小。這個過程,就可以認為是在施加不同大小的注意力在各個特徵通道上。
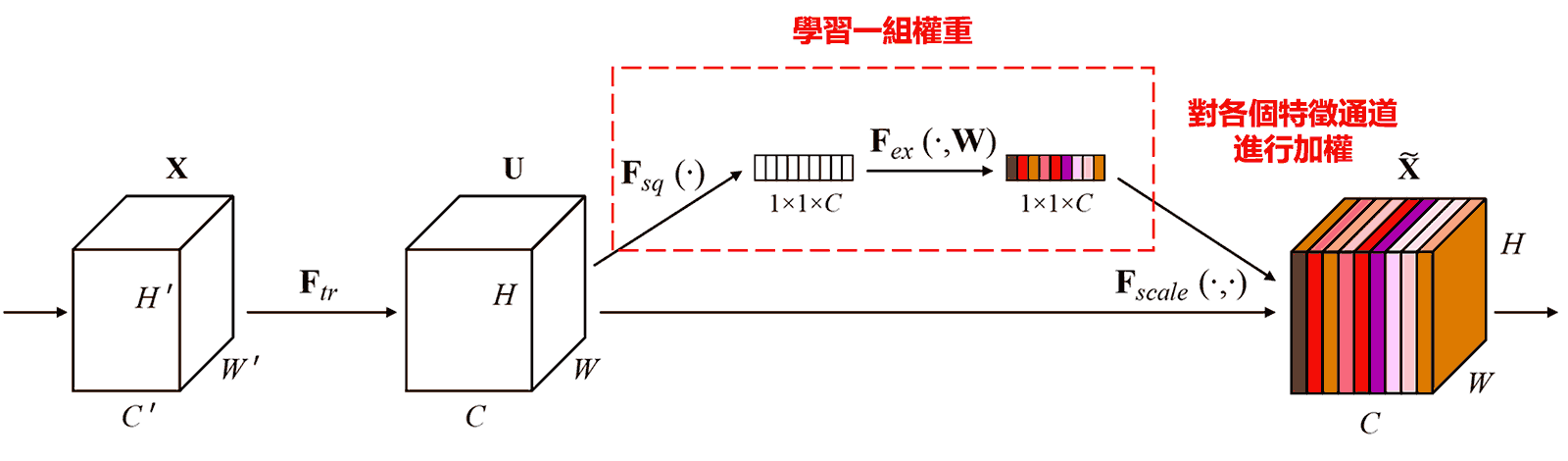
在這種方式下,每一個樣本,都會有自己獨立的一組權重。換言之,任意的兩個樣本,它們的權重,都是不一樣的。在SENet中,獲得權重的具體路徑是,「全域池化→全連接層→ReLU函數→全連接層→Sigmoid函數」。
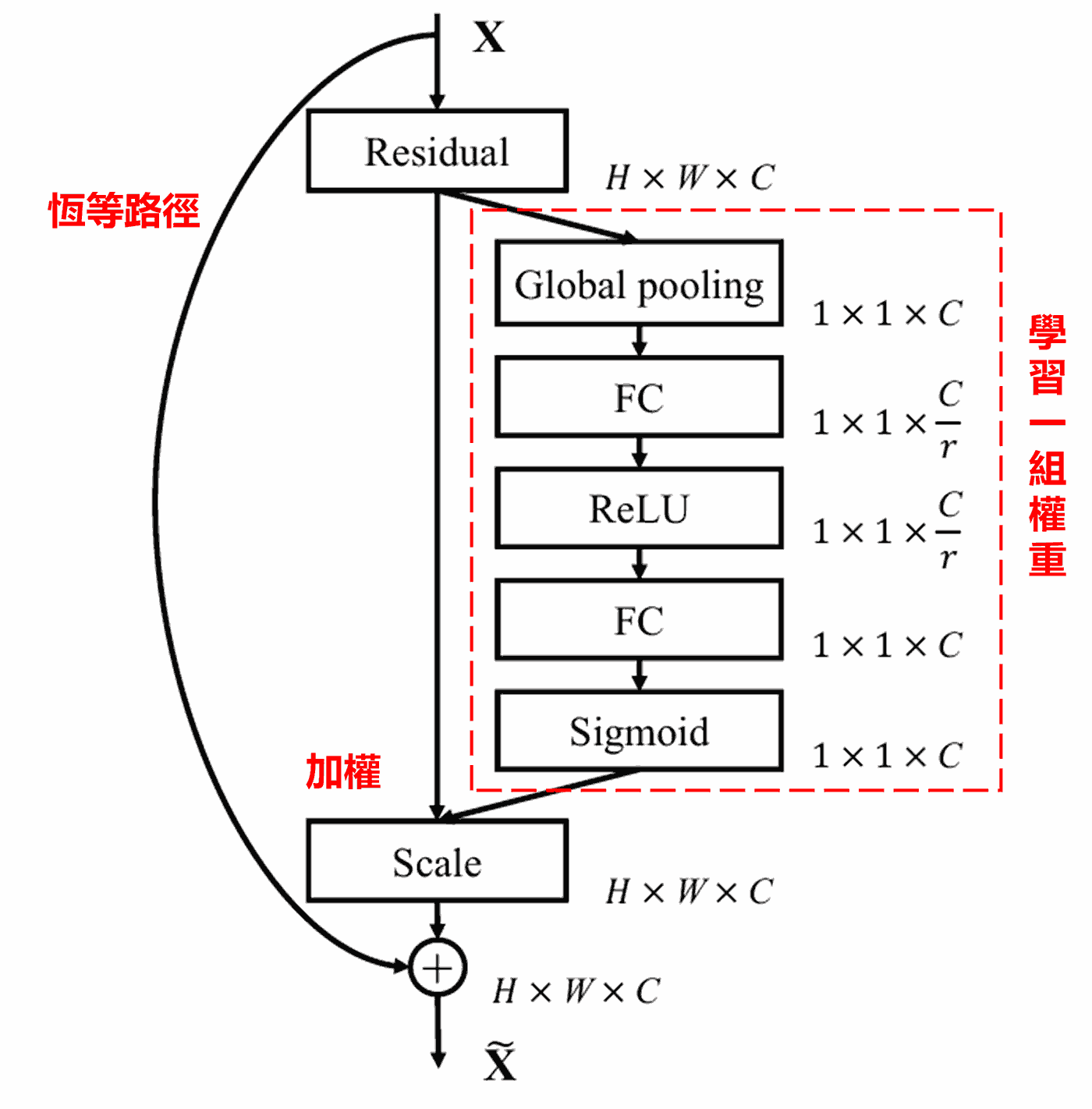
4. 深度注意力機制下的軟閾值化
深度殘差收縮網路參考了上述SENet的子網路結構,以實現深度注意力機制下的軟閾值化。透過紅色框內的子網路,就可以學習得到一組閾值,對各個特徵通道進行軟閾值化。
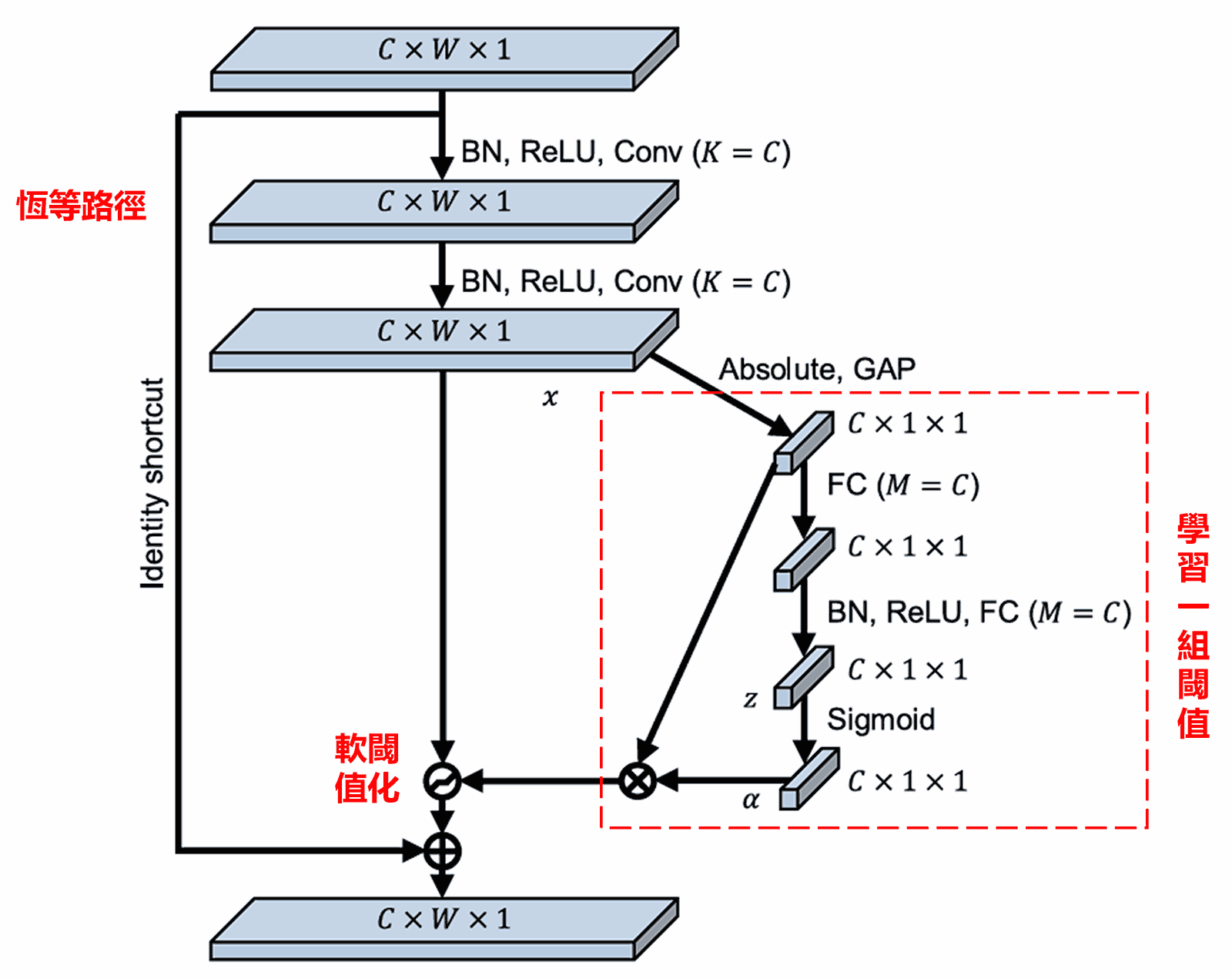
在這個子網路中,首先對輸入特徵圖的所有特徵,取它們的絕對值。然後經過全域平均池化和平均,獲得一個特徵,記為A。在另一條路徑中,全域平均池化之後的特徵圖,被輸入到一個小型全連接網路。這個全連接網路以Sigmoid函數作為最後一層,將輸出正規化到0和1之間,獲得一個係數,記為α。最終的閾值可以表示為α×A。因此閾值就是:一個0和1之間的數字×特徵圖的絕對值的平均。這種方式,不僅保證了閾值為正,而且不會太大。
而且,不同的樣本就有了不同的閾值。因此,在一定程度上,可以理解成一種特殊的注意力機制:注意到與當前任務無關的特徵,透過兩個卷積層將這些特徵轉換成接近0的特徵,透過軟閾值化將這些特徵置為零;換句話說,注意到與當前任務有關的特徵,透過兩個卷積層將這些特徵轉換成遠離0的特徵,將這些特徵保留下來。
最後,堆疊一定數量的基本模組以及卷積層、批次正規化(Batch Normalization)、激勵函數、全域平均池化以及全連接輸出層等,就得到了完整的深度殘差收縮網路。
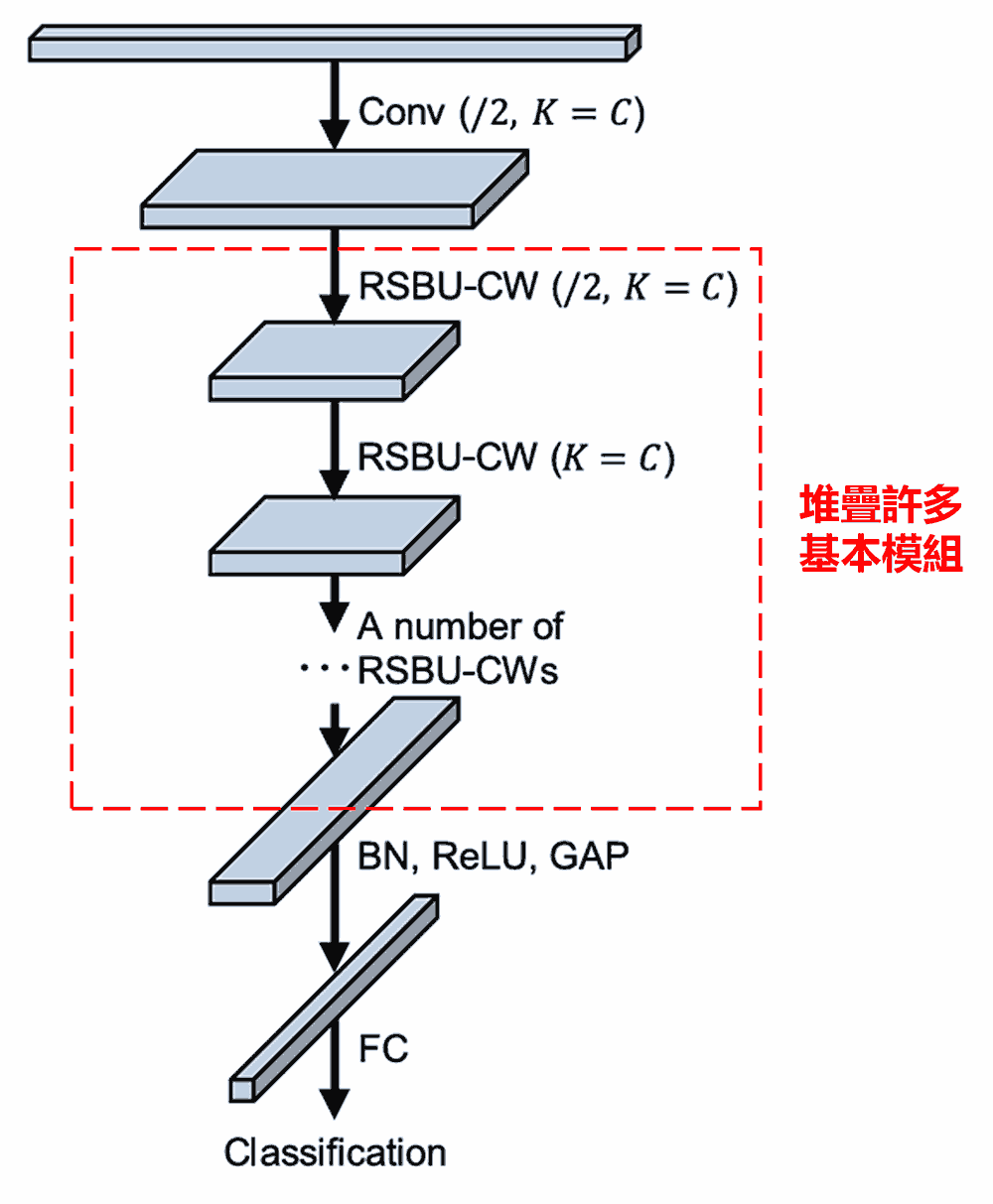
5. 通用性
深度殘差收縮網路事實上是一種通用的特徵學習方法。這是因為很多特徵學習的任務中,樣本中或多或少都會包含一些雜訊,以及不相關的資訊。這些雜訊和不相關的資訊,有可能會對特徵學習的效果造成影響。例如說:
在影像分類的時候,如果影像同時包含著很多其他的物體,那麼這些物體就可以被理解成「雜訊」;深度殘差收縮網路或許能夠借助注意力機制,注意到這些「雜訊」,然後借助軟閾值化,將這些「雜訊」所對應的特徵置為零,就有可能提高影像分類的準確率。
在語音辨識的時候,如果在聲音較為嘈雜的環境裡,比如在馬路邊、工廠廠房裡聊天的時候,深度殘差收縮網路也許可以提高語音辨識的準確率,或者給出了一種能夠提高語音辨識準確率的新構想。
參考文獻
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
影響力情況
該論文的Google Scholar引用次數已經超過1400次。
根據不完全統計,深度殘差收縮網路已經被超過1000篇文獻直接應用或改良後應用於機械、電力、視覺、醫療、語音、文字、雷達、遙測等眾多領域。