Deep Residual Shrinkage Network (DRSN) là một biến thể nâng cấp của Deep Residual Network (ResNet). Về bản chất, đây là sự kết hợp giữa kiến trúc ResNet, cơ chế Attention và hàm Soft Thresholding.
Hiểu một cách đơn giản, nguyên lý hoạt động của DRSN là: sử dụng cơ chế Attention để “nhận diện” các đặc trưng (features) không quan trọng, sau đó dùng hàm Soft Thresholding để gán giá trị của chúng về 0. Ngược lại, các feature quan trọng sẽ được giữ lại. Cơ chế này giúp model Deep Learning tăng cường đáng kể khả năng trích xuất thông tin hữu ích ngay cả khi tín hiệu đầu vào chứa nhiều nhiễu.
1. Động lực nghiên cứu (Motivation)
Thứ nhất, trong các bài toán phân loại thực tế, dữ liệu đầu vào hầu như luôn chứa nhiễu (noise), chẳng hạn như Gaussian noise, Pink noise, Laplacian noise, v.v. Nói rộng hơn, bất kỳ thông tin nào trong mẫu dữ liệu mà không liên quan đến task phân loại hiện tại đều có thể xem là nhiễu. Những nhiễu này ảnh hưởng xấu đến độ chính xác (accuracy) của mô hình. (Lưu ý rằng Soft Thresholding là bước then chốt trong nhiều thuật toán xử lý tín hiệu để khử nhiễu).
Ví dụ: Khi chúng ta nói chuyện ngoài đường, âm thanh thu được sẽ lẫn tạp âm như tiếng còi xe, tiếng bánh xe… Khi thực hiện nhận dạng giọng nói (Speech Recognition), kết quả chắc chắn sẽ bị ảnh hưởng. Từ góc độ Deep Learning, các feature đại diện cho tiếng còi hay tiếng bánh xe cần phải được loại bỏ ngay bên trong mạng neural (network) để tránh gây nhiễu cho kết quả dự đoán.
Thứ hai, ngay cả trong cùng một tập dữ liệu (dataset), lượng nhiễu trong từng mẫu (sample) cũng thường khác nhau. (Điểm này rất tương đồng với cơ chế Attention. Ví dụ trong một bộ ảnh, vị trí vật thể ở mỗi ảnh là khác nhau, và Attention giúp model focus vào đúng vị trí đó).
Hãy tưởng tượng bạn đang train một model phân loại chó-mèo. Giả sử có 5 bức ảnh nhãn “chó”. Ảnh 1 có chó và chuột, Ảnh 2 có chó và ngỗng, Ảnh 3 có chó và gà, v.v. Khi train model, chắc chắn việc học sẽ bị can nhiễu bởi các đối tượng không liên quan (chuột, ngỗng, gà…), làm giảm độ chính xác. Nếu ta có thể giúp model tự động “chú ý” và loại bỏ feature của những con vật thừa thãi này, hiệu suất của bộ phân loại sẽ được cải thiện rõ rệt.
2. Kỹ thuật Soft Thresholding
Soft Thresholding là trái tim của nhiều thuật toán khử nhiễu. Cơ chế của nó là: loại bỏ các feature có giá trị tuyệt đối nhỏ hơn một ngưỡng (threshold) nhất định, và “co” (shrink) các feature có giá trị lớn hơn ngưỡng này về hướng 0. Công thức cụ thể như sau:
\[y = \begin{cases} x - \tau & x > \tau \\ 0 & -\tau \le x \le \tau \\ x + \tau & x < -\tau \end{cases}\]Đạo hàm của hàm Soft Thresholding theo đầu vào là:
\[\frac{\partial y}{\partial x} = \begin{cases} 1 & x > \tau \\ 0 & -\tau \le x \le \tau \\ 1 & x < -\tau \end{cases}\]Dễ thấy, đạo hàm của nó chỉ trả về 1 hoặc 0. Tính chất này giống hệt hàm kích hoạt ReLU. Nhờ vậy, Soft Thresholding cũng giúp giảm thiểu rủi ro gặp lỗi Gradient Vanishing (biến mất đạo hàm) và Gradient Exploding (bùng nổ đạo hàm) khi train Deep Learning.
Khi dùng Soft Thresholding, ngưỡng (threshold) cần thỏa mãn hai điều kiện:
- Ngưỡng phải là số dương.
- Ngưỡng không được lớn hơn giá trị cực đại của tín hiệu đầu vào (nếu không output sẽ toàn là số 0).
Đặc biệt, ngưỡng tốt nhất nên thỏa mãn điều kiện thứ ba: Mỗi sample cần có một ngưỡng thích ứng riêng (adaptive threshold), dựa trên lượng nhiễu của chính nó.
Lý do rất đơn giản: mẫu A ít nhiễu thì nên dùng ngưỡng nhỏ, mẫu B nhiều nhiễu thì cần ngưỡng lớn hơn để lọc sạch. Trong Deep Neural Network, dù các feature và ngưỡng không còn ý nghĩa vật lý tường minh như xử lý tín hiệu cổ điển, nhưng logic cơ bản vẫn giữ nguyên: Mỗi sample cần được xử lý với một ngưỡng riêng biệt.
3. Cơ chế Attention (Attention Mechanism)
Attention trong Computer Vision khá dễ hình dung. Giống như mắt người quét nhanh toàn cảnh để tìm mục tiêu, sau đó tập trung sự chú ý vào đó để soi chi tiết và lờ đi phần nền xung quanh.
Squeeze-and-Excitation Network (SENet) là một kiến trúc tiêu biểu sử dụng Attention. Trong các sample khác nhau, mức độ đóng góp của các feature channel vào kết quả phân loại là khác nhau. SENet dùng một mạng con (subnet) nhỏ để học ra một bộ trọng số (weights), sau đó nhân các weight này với feature của từng channel để điều chỉnh độ lớn của chúng. Quá trình này chính là gán các mức độ “quan trọng” khác nhau lên từng channel.
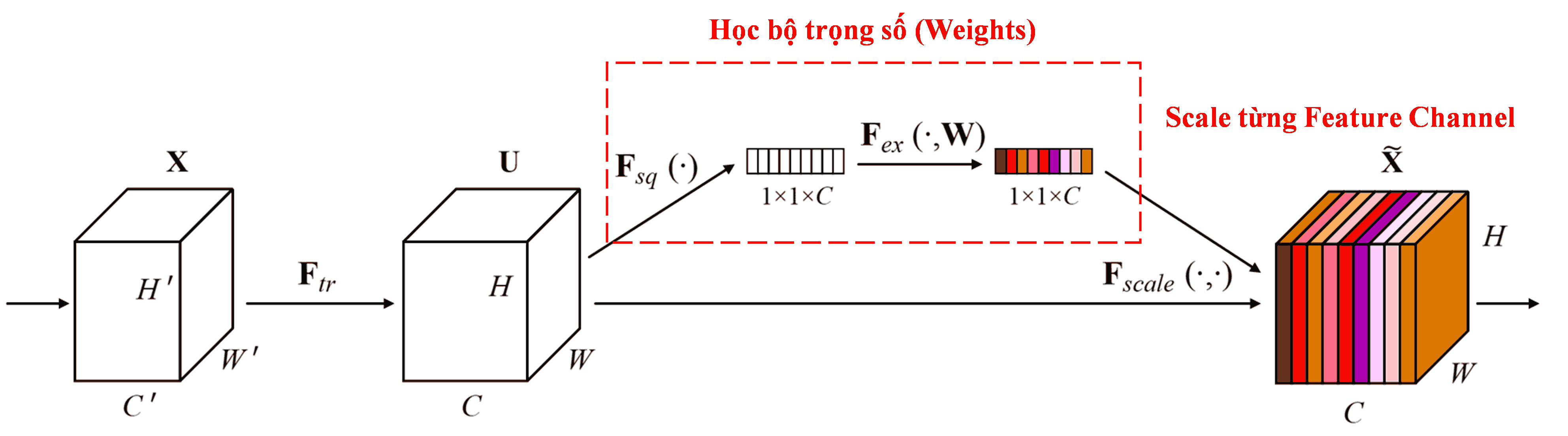
Theo cách này, mỗi sample sẽ có một bộ weight riêng. Luồng xử lý (pipeline) của SENet là: “Global Average Pooling → Fully Connected Layer → ReLU → Fully Connected Layer → Sigmoid”.
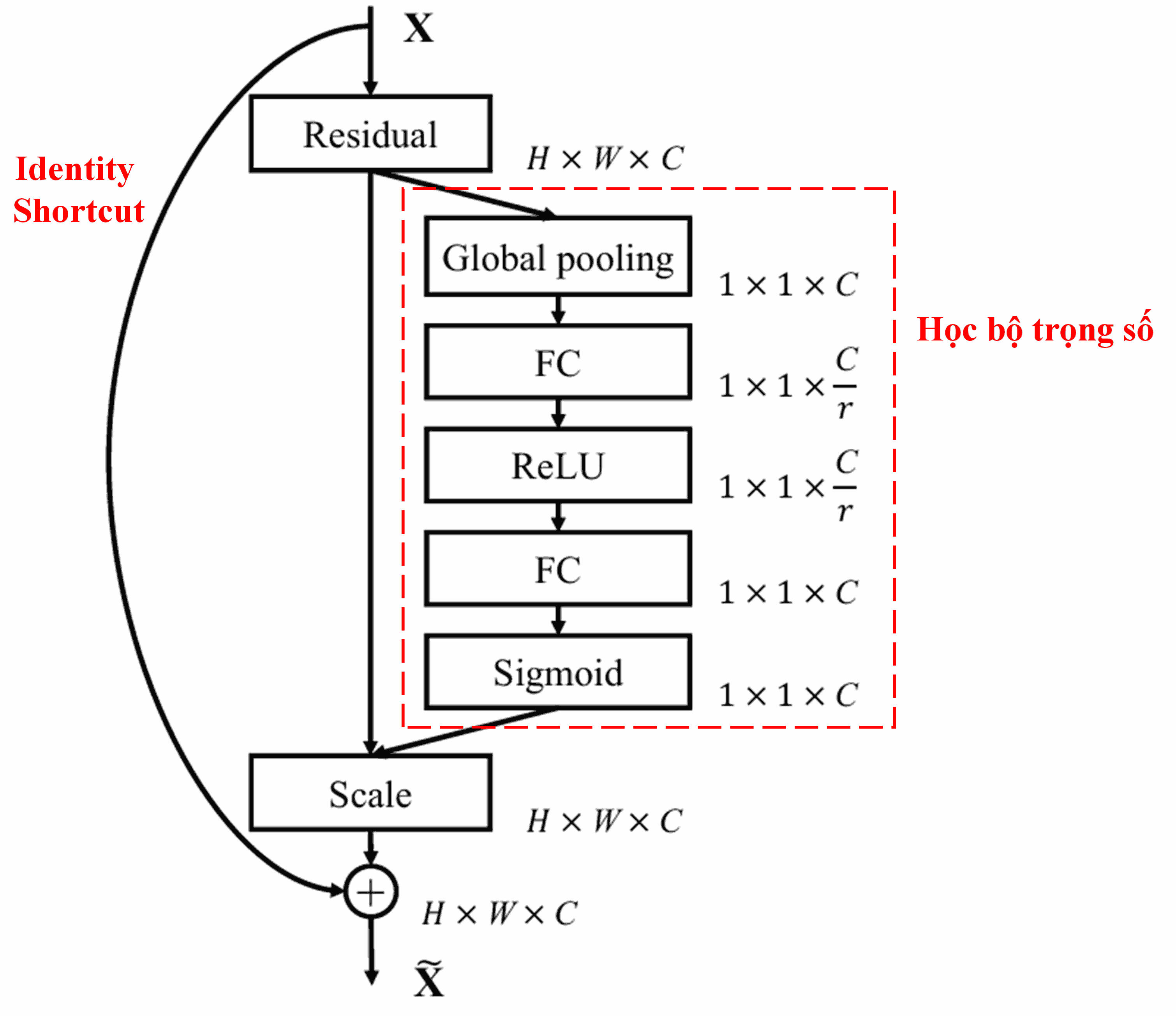
4. Kết hợp Soft Thresholding và Deep Attention
Deep Residual Shrinkage Network (DRSN) tham khảo cấu trúc subnet của SENet để thực thi Soft Thresholding dưới cơ chế Attention. Thông qua subnet (phần trong khung màu đỏ), model sẽ tự học được một bộ ngưỡng để áp dụng Soft Thresholding cho từng feature channel.
Trong subnet này:
- Đầu tiên tính giá trị tuyệt đối của input feature map.
- Đi qua Global Average Pooling để thu được đặc trưng A.
- Ở nhánh còn lại, feature map sau khi pooling được đưa vào một mạng Fully Connected nhỏ.
- Lớp cuối cùng dùng hàm Sigmoid để chuẩn hóa output về khoảng [0, 1], thu được hệ số α.
- Ngưỡng cuối cùng được tính bằng công thức: τ = α × A.
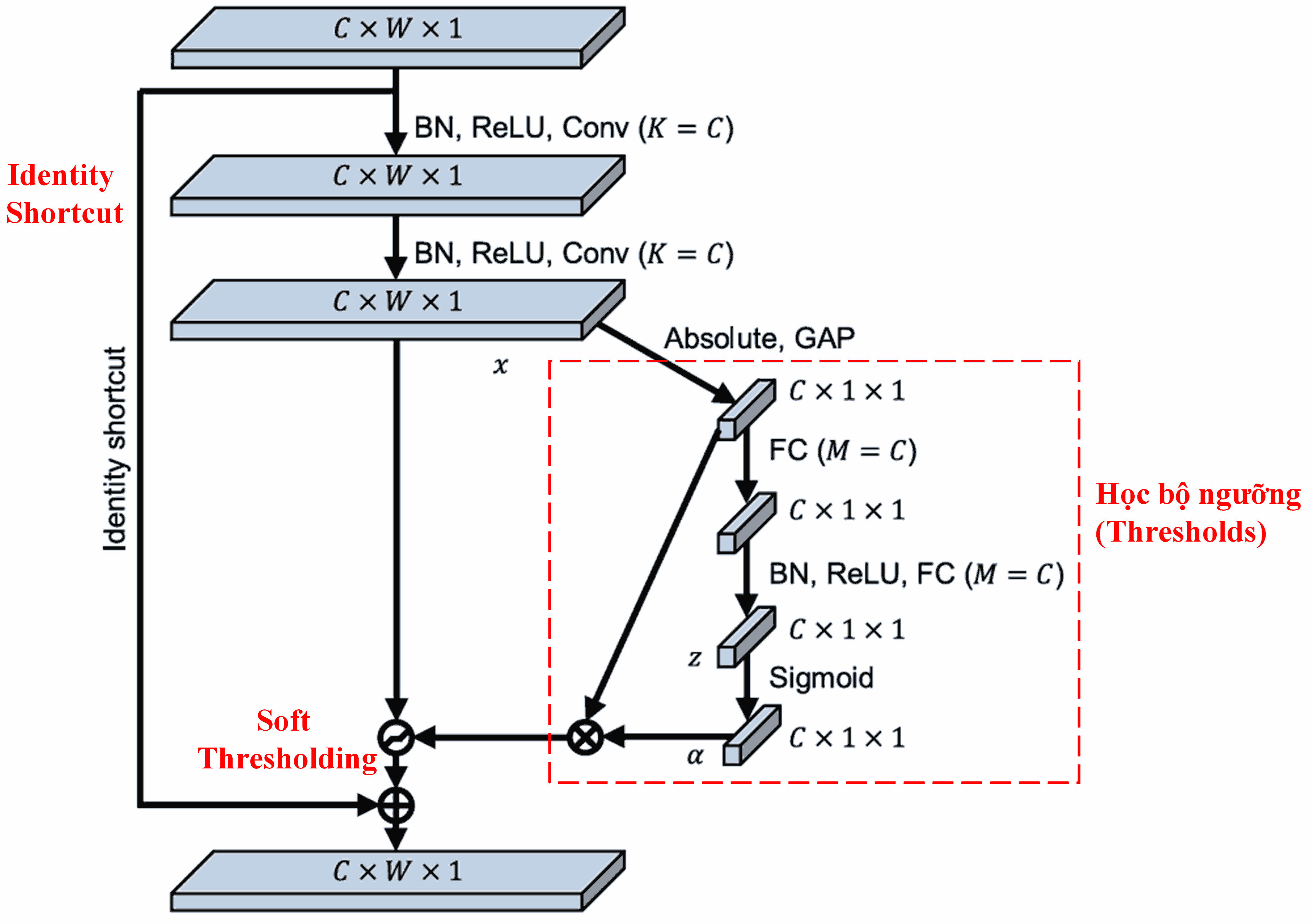
Tức là: ngưỡng bằng một số trong khoảng [0, 1] nhân với giá trị trung bình tuyệt đối của feature map. Cách này đảm bảo ngưỡng luôn dương và độ lớn hợp lý.
Quan trọng hơn, các sample khác nhau sẽ sinh ra các ngưỡng khác nhau. Đây có thể xem là một dạng Attention đặc biệt: model tự nhận diện feature nào là nhiễu để “ép” về 0 (thông qua Soft Thresholding), và feature nào quan trọng để giữ lại.
Cuối cùng, bằng việc xếp chồng các block cơ bản này cùng các lớp Convolution, Batch Normalization, Activation function, Global Average Pooling và lớp Fully Connected output, ta xây dựng được một mạng Deep Residual Shrinkage Network hoàn chỉnh.
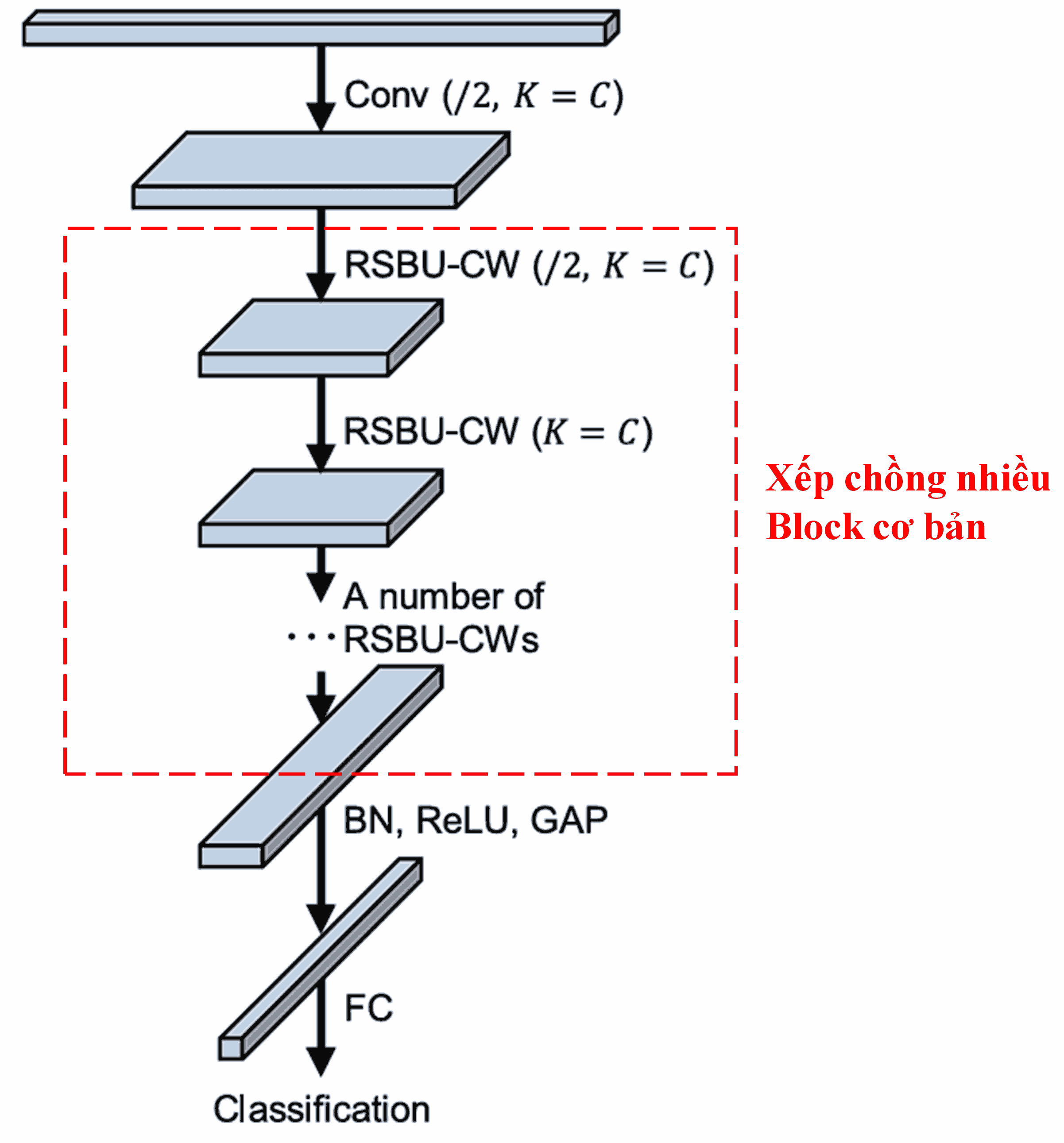
5. Tính phổ quát (Generalization)
DRSN thực tế là một phương pháp học đặc trưng (feature learning) có tính phổ quát cao, vì đa số dữ liệu thực tế đều chứa nhiễu hoặc thông tin dư thừa.
- Trong Image Classification: nếu ảnh chứa nhiều vật thể nền gây nhiễu, DRSN dùng Attention để phát hiện và Soft Thresholding để triệt tiêu các feature của vùng nhiễu này, giúp tăng accuracy.
- Trong Speech Recognition: nếu môi trường thu âm ồn (đường phố, nhà xưởng), phương pháp này cung cấp một hướng tiếp cận tiềm năng để lọc nhiễu và cải thiện kết quả nhận dạng.
Tài liệu tham khảo
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Michael Pecht, Deep residual shrinkage networks for fault diagnosis, IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
https://ieeexplore.ieee.org/document/8850096
BibTeX
@article{Zhao2020,
author = {Minghang Zhao and Shisheng Zhong and Xuyun Fu and Baoping Tang and Michael Pecht},
title = {Deep Residual Shrinkage Networks for Fault Diagnosis},
journal = {IEEE Transactions on Industrial Informatics},
year = {2020},
volume = {16},
number = {7},
pages = {4681-4690},
doi = {10.1109/TII.2019.2943898}
}
Tầm ảnh hưởng
Bài báo này hiện đã đạt hơn 1.400 trích dẫn trên Google Scholar.
Theo thống kê chưa đầy đủ, Deep Residual Shrinkage Network đã được ứng dụng (hoặc cải tiến) trong hơn 1.000 công trình nghiên cứu thuộc nhiều lĩnh vực đa dạng như: Cơ khí, Điện lực, Computer Vision, Y tế, Xử lý tiếng nói & văn bản, Radar và Viễn thám (Remote Sensing).